
챗봇 환각 현상, 이제 그만! RAG가 기업 LLM의 구원투수인 이유
RAG(Retrieval-Augmented Generation)는 외부 지식 검색을 통해 LLM의 환각 현상을 획기적으로 줄이고 최신성을 확보하는 기술입니다. 왜냐하면 LLM이 답변 생성 전에 검증된 외부 데이터를 참조하도록 만들기 때문입니다. 기존 LLM은 학습 데이터에 없는 질문이나 최신 정보에 대해 잘못된 정보를 생성하는 '환각(Hallucination)' 현상으로 인해 기업 환경에서의 신뢰성 확보에 어려움을 겪었습니다. 예를 들어, 기업 내부 정책이나 실시간 재고 정보에 대한 질문에 LLM은 그럴듯하지만 사실과 다른 답변을 내놓을 수 있으며, 이는 비즈니스 의사결정에 심각한 문제를 야기할 수 있습니다.
이러한 한계를 극복하기 위해 등장한 RAG는 2026년 기준, 기업용 AI 챗봇 및 지식 시스템의 핵심 기술로 자리 잡고 있습니다. Forrester Research의 2025년 보고서에 따르면, RAG를 도입한 기업은 LLM 기반 애플리케이션의 정보 정확도를 평균 2배 향상시키고, 환각 현상을 50% 이상 감소시키는 효과를 보고 있습니다. 특히 고객 서비스, 법률 자문, 의료 진단 지원과 같은 고신뢰성 요구 분야에서 RAG의 도입은 필수적인 요소로 간주되고 있으며, 이는 곧 기업의 경쟁력으로 직결되고 있습니다.
RAG는 대규모 언어 모델이 답변을 생성하기 전에 관련성 높은 정보를 외부 데이터베이스에서 검색하고, 그 정보를 기반으로 답변을 생성하도록 돕는 프레임워크입니다. 이는 마치 LLM에게 필요한 정보를 미리 찾아 제공하는 '오픈 북(Open-book)' 시험과 유사합니다. 이를 통해 LLM은 학습 데이터의 한계를 넘어서는 최신 정보를 활용하고, 기업 내부의 민감하거나 특화된 데이터에 기반한 정확하고 신뢰할 수 있는 답변을 제공할 수 있게 됩니다. 결국 RAG는 LLM의 잠재력을 최대한 발휘하면서도 그 단점을 보완하는 강력한 솔루션입니다.

RAG 애플리케이션, 어떻게 작동할까요? 핵심 구성 요소와 원리 파헤치기
RAG 시스템은 여러 핵심 구성 요소들이 유기적으로 결합하여 작동합니다. 이 프로세스는 크게 데이터 준비, 임베딩, 벡터 데이터베이스 저장, 검색, 그리고 LLM 답변 생성의 5단계로 나눌 수 있습니다. 각 단계는 RAG 애플리케이션의 성능과 정확도에 결정적인 영향을 미치므로, 각 구성 요소의 역할과 상호작용을 명확히 이해하는 것이 중요합니다.
가장 먼저, 기업 내부에 흩어져 있는 문서, 데이터베이스, 웹페이지 등 비정형 및 정형 데이터를 수집하고 정제하여 LLM이 처리하기 쉬운 형태로 만듭니다. 이 데이터를 '청크(Chunk)'라고 불리는 작은 단위로 분할한 뒤, '임베딩(Embedding) 모델'을 사용하여 각 청크를 숫자 벡터(Vector)로 변환합니다. 이 벡터는 해당 청크의 의미를 고차원 공간에 표현하며, 의미적으로 유사한 청크들은 서로 가까운 벡터 공간에 위치하게 됩니다. 대표적인 임베딩 모델로는 OpenAI Embeddings나 Hugging Face Sentence Transformers 등이 있습니다. 이 과정은 OpenAI 공식 문서에서 자세히 다루고 있습니다.
이렇게 생성된 벡터들은 '벡터 데이터베이스(Vector Database)'에 저장됩니다. 벡터 데이터베이스는 수많은 벡터들 중에서 사용자 질문과 가장 유사한 벡터를 효율적으로 찾아내는 데 특화되어 있습니다. ChromaDB, Pinecone, Weaviate 등이 널리 사용되는 벡터 데이터베이스의 예시입니다. 사용자가 LLM에 질문을 하면, 이 질문 또한 임베딩 모델을 통해 벡터로 변환되고, 이 질문 벡터를 바탕으로 벡터 데이터베이스에서 가장 유사한 문서 청크들을 검색합니다. 이 검색된 청크들이 바로 LLM이 답변을 생성하는 데 필요한 '추가 컨텍스트(Context)'가 되는 것입니다. 마지막으로, LLM은 사용자 질문과 함께 검색된 컨텍스트를 받아 최종 답변을 생성하게 됩니다. 이러한 일련의 과정을 Langchain이나 LlamaIndex와 같은 LLM 오케스트레이션 프레임워크가 효율적으로 관리합니다.

기업 데이터 기반 RAG 애플리케이션 개발 5단계 실전 가이드 (코드 예시 포함)
이제 실제 기업 데이터를 활용하여 RAG 애플리케이션을 개발하는 구체적인 5단계 과정을 살펴보겠습니다. 여기서는 Langchain 프레임워크와 ChromaDB, 그리고 OpenAI LLM/임베딩 모델을 기반으로 한 예시 코드를 제시합니다. 이 가이드는 2026년 4월 현재 가장 널리 사용되는 기술 스택을 반영하며, 여러분의 개발 시간을 획기적으로 단축시켜 줄 것입니다.
1단계: 기업 데이터 준비 및 로딩
기업 내부에 존재하는 PDF, DOCX, CSV 등 다양한 형식의 문서를 로드하는 단계입니다. Langchain은 다양한 문서 로더(Document Loader)를 제공하여 이 과정을 간소화합니다. 예를 들어, 회사 내부 규정집 PDF 파일을 로드한다고 가정해 봅시다.from langchain_community.document_loaders import PyPDFLoader
# 회사 정책 문서 로드
loader = PyPDFLoader("data/corporate_policy.pdf")
documents = loader.load()
print(f"로드된 문서 수: {len(documents)}") # 예: 로드된 문서 수: 1
print(f"첫 번째 문서 내용의 일부: {documents[0].page_content[:100]}...")corporate_policy.pdf 파일을 로드하여 documents 리스트에 저장합니다. 여러 파일을 로드하거나 웹 페이지, 데이터베이스 등 다른 소스의 데이터를 로드할 때도 유사한 패턴을 따릅니다.2단계: 효율적인 청킹(Chunking) 전략 수립
로드된 문서를 LLM이 처리하기 적합한 크기의 청크로 분할하는 과정입니다. 너무 크면 LLM의 컨텍스트 창을 초과하고, 너무 작으면 문맥이 손실될 수 있으므로, 적절한 청크 크기와 오버랩(Overlap) 설정이 중요합니다. 일반적으로 500~1000자 청크에 100~200자 오버랩을 권장합니다.from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 청크당 최대 문자 수
chunk_overlap=200, # 청크 간 겹치는 문자 수
length_function=len
)
chunks = text_splitter.split_documents(documents)
print(f"생성된 청크 수: {len(chunks)}") # 예: 생성된 청크 수: 50
print(f"첫 번째 청크 내용의 일부: {chunks[0].page_content[:100]}...")RecursiveCharacterTextSplitter는 문서 구조를 고려하여 분할을 시도하므로, 일반 텍스트 분할기보다 더 나은 결과를 제공합니다. 이 과정은 Langchain 공식 튜토리얼에서도 강조되는 부분입니다. 또한, 다른 LLM 파인튜닝 전략에 관심 있다면 AI웍스의 LLM 비용 효율적 파인튜닝 실전 가이드 글도 참고해 보세요.3단계: 임베딩 및 벡터 데이터베이스 구축
분할된 청크들을 임베딩 모델로 벡터화하고, 이를 벡터 데이터베이스에 저장합니다. 여기서는 OpenAI의 임베딩 모델과 로컬에서 쉽게 사용할 수 있는 ChromaDB를 활용합니다. API 키는 환경 변수로 설정하는 것이 좋습니다.from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# 임베딩 모델 초기화
embeddings = OpenAIEmbeddings()
# 벡터 데이터베이스(Chroma) 구축 및 청크 저장
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 로컬에 저장할 경로
)
# 영속화된 DB 로드 (다음 실행 시)
# vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
print("벡터 데이터베이스 구축 및 저장 완료.")Chroma.from_documents 함수는 청크들을 자동으로 임베딩하고 벡터 데이터베이스에 저장합니다. persist_directory를 지정하면 벡터 데이터베이스가 로컬 파일 시스템에 저장되어, 애플리케이션을 다시 시작해도 데이터를 유지할 수 있습니다.4단계: 검색기(Retriever) 설계 및 LLM 연동
벡터 데이터베이스에서 관련 청크를 검색하고, 검색된 청크와 사용자 질문을 LLM에 전달하여 답변을 생성하는 체인(Chain)을 구성합니다.from langchain.chat_models import ChatOpenAI
from langchain.chains import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# LLM 초기화
llm = ChatOpenAI(model_name="gpt-4o", temperature=0.1)
# RAG 프롬프트 템플릿 정의
prompt = ChatPromptTemplate.from_template(
"""제공된 문맥을 사용하여 질문에 답하세요. 만약 문맥에서 답을 찾을 수 없다면, 모른다고 답하세요.
문맥:
{context}
질문: {input}
"""
)
# 문서 체인 생성
document_chain = create_stuff_documents_chain(llm, prompt)
# 검색기 설정
retriever = vectorstore.as_retriever()
print("검색기 및 문서 체인 구성 완료.")create_stuff_documents_chain은 검색된 모든 문서를 하나의 문자열로 결합하여 LLM에 전달하는 일반적인 RAG 패턴을 구현합니다. 프롬프트 템플릿에 context 변수를 포함시켜 LLM이 검색된 정보를 활용하도록 지시하는 것이 핵심입니다. 2025년 12월, Google Research는 이러한 프롬프트 구성의 중요성을 강조하는 보고서를 발표하기도 했습니다.5단계: RAG 쿼리 체인 실행 및 결과 확인
이제 구성된 검색기와 문서 체인을 결합하여 최종 RAG 쿼리 체인을 만들고, 실제 질문을 던져 답변을 확인합니다.from langchain.chains import create_retrieval_chain
# 검색 체인 생성
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 질문 실행
response = retrieval_chain.invoke({"input": "AI웍스의 휴가 정책에 대해 알려줘."}) # 기업 정책에 대한 질문
print(f"질문: {response['input']}")
print(f"검색된 문서:")
for doc in response['context']:
print(f"- {doc.page_content[:50]}...")
print(f"답변: {response['answer']}")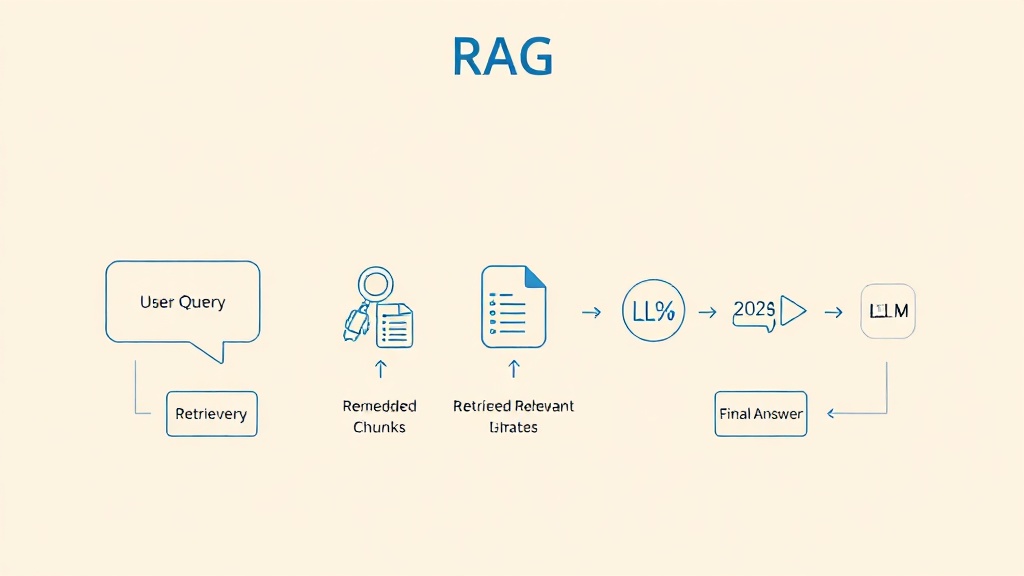
LLM 정확도 2배, 환각 현상 50% 감소! RAG 성능 최적화 고급 기법
기본적인 RAG 시스템은 LLM의 정확도를 크게 향상시키지만, 더 높은 성능과 사용자 경험을 위해서는 몇 가지 고급 최적화 기법을 적용하는 것이 필수적입니다. 이러한 기법들은 검색된 문서의 관련성을 극대화하고, LLM에 전달되는 컨텍스트를 더욱 정교하게 만들어 LLM의 환각을 추가적으로 줄이며 응답 품질을 높입니다. 2025년 Anthropic은 LLM이 처리하는 컨텍스트의 품질이 최종 답변의 신뢰성에 미치는 영향이 매우 크다는 연구 결과를 발표하며, 이러한 최적화의 중요성을 강조했습니다.
첫 번째로 '쿼리 확장(Query Expansion)'은 사용자 질문을 다양한 방식으로 변형하거나 관련 키워드를 추가하여 검색 범위를 넓히는 기법입니다. 예를 들어, 'AI웍스 휴가'라는 질문을 'AI웍스 연차 정책', 'AI웍스 유급 휴가 규정' 등으로 확장하여 벡터 데이터베이스에서 더 많은 관련 문서를 찾아낼 수 있습니다. 두 번째는 '리랭킹(Reranking)'으로, 벡터 검색을 통해 얻은 초기 결과물들을 다시 한번 더 정밀하게 평가하여 가장 관련성 높은 문서들을 LLM에 전달하는 과정입니다. 이는 검색된 문서들의 순위를 재조정하여 LLM이 가장 중요한 정보에 집중하도록 돕습니다. Cohere Rerank나 Hugging Face Rankers 같은 전용 모델을 활용할 수 있습니다.
세 번째 기법은 '컨텍스트 압축(Context Compression)'입니다. 검색된 문서들 중 질문과 직접적으로 관련 없는 부분을 제거하고 핵심 내용만 압축하여 LLM에 전달하는 방식입니다. 이는 LLM의 컨텍스트 창(Context Window) 제약을 효과적으로 관리하고, 중요한 정보에 대한 LLM의 집중도를 높여줍니다. 마지막으로 '하이브리드 검색(Hybrid Search)'은 키워드 기반 검색(예: BM25)과 벡터 기반 시맨틱 검색을 결합하는 방법입니다. 키워드 검색은 특정 용어나 고유명사 검색에 강하고, 벡터 검색은 의미론적 유사성 검색에 강하므로, 이 둘을 조합하면 검색의 정확도와 포괄성을 동시에 높일 수 있습니다.
이러한 고급 최적화 기법들을 적용하면 RAG 시스템의 성능을 비약적으로 향상시킬 수 있습니다. 아래 표는 기본적인 RAG와 최적화된 RAG의 주요 차이점을 비교합니다. 최적화된 RAG는 초기 설정 복잡도가 높지만, 결과적으로 LLM의 정확도를 극대화하고 사용자 만족도를 높여 기업 비즈니스에 더 큰 가치를 제공합니다.
| 기준 (Criteria) | 기본 RAG (Basic RAG) | 최적화된 RAG (Optimized RAG) |
|---|---|---|
| 복잡도 (Complexity) | 낮음 (Low) | 높음 (High) |
| 초기 설정 (Initial Setup) | 빠름 (Fast) | 시간 소요 (Time-consuming) |
| 성능 (Performance) | 양호 (Good) | 매우 우수 (Excellent) |
| 비용 (Cost) | 낮음-중간 (Low-Medium) | 중간-높음 (Medium-High) |
| 주요 이점 (Key Benefits) | 환각 감소, 최신 정보 활용 (Reduced hallucinations, up-to-date info) | 정확도 극대화, 정교한 답변 (Maximized accuracy, refined answers) |
핵심 요약: RAG 애플리케이션 개발은 LLM의 환각 현상을 줄이고 정확도를 높이는 필수적인 방법입니다. 데이터 준비부터 임베딩, 벡터 DB 구축, LLM 연동까지 5단계 과정을 통해 실질적인 시스템을 구축할 수 있습니다. 쿼리 확장, 리랭킹, 컨텍스트 압축과 같은 고급 기법을 적용하면 LLM 성능을 더욱 최적화할 수 있습니다. 2026년 기업 AI 시스템의 성공적인 도입을 위해 RAG는 핵심적인 역할을 할 것입니다.

자주 묻는 질문
Q. RAG 개발 시 가장 중요한 요소는 무엇인가요? A. RAG 개발에서 가장 중요한 요소는 '데이터 품질'과 '청킹 전략', 그리고 '임베딩 모델 선택'입니다. 고품질의 기업 데이터를 정확하게 청킹하고, 해당 데이터의 의미를 잘 표현하는 임베딩 모델을 사용하는 것이 검색 정확도를 높이고 LLM의 답변 품질을 결정하는 핵심입니다. 데이터가 불량하거나 청크가 부적절하면 아무리 좋은 LLM을 사용해도 원하는 결과를 얻기 어렵습니다.
Q. 벡터 데이터베이스는 어떤 기준으로 선택해야 하나요? A. 벡터 데이터베이스 선택 시에는 데이터의 규모, 검색 속도 요구사항, 비용, 관리 편의성, 그리고 클라우드 또는 온프레미스 배포 요구사항을 고려해야 합니다. 소규모 프로젝트나 프로토타이핑에는 ChromaDB나 Faiss처럼 로컬에서 쉽게 사용할 수 있는 옵션이 좋고, 대규모 프로덕션 환경에는 Pinecone, Weaviate, Milvus와 같은 클라우드 기반 또는 분산형 벡터 데이터베이스가 더 적합합니다. 2025년 IDC 보고서에 따르면, 클라우드 기반 벡터DB 시장은 매년 30% 이상 성장하고 있습니다.
Q. RAG만으로 환각 현상을 100% 제거할 수 있나요? A. RAG는 LLM의 환각 현상을 획기적으로 줄여주지만, 100% 완전히 제거하는 것은 어렵습니다. RAG는 외부 정보를 기반으로 답변의 신뢰도를 높이지만, LLM 자체의 추론 오류나 검색된 정보의 한계로 인해 여전히 미미한 수준의 환각이 발생할 수 있습니다. 따라서 RAG를 적용하더라도 지속적인 모니터링, 답변 검증, 그리고 사용자 피드백을 통한 시스템 개선 노력이 필요합니다. 이는 LLM의 본질적인 한계를 이해하고 보완하는 과정입니다.
참고자료
- The state of AI in 2023: Generative AI’s breakout year - McKinsey (2023)
- What is Generative AI? - Gartner (2024)
- LangChain Documentation - LangChain (2026)
- Embeddings - OpenAI Platform (2026)
- ChromaDB Documentation - Chroma (2026)
이 글이 도움이 되셨다면 공유해 주세요.


