
기업 LLM의 한계, RAG로 극복하는 방법 (feat. 답변 정확도 30% 향상)
기업 특화 LLM 지식 검색 시스템은 RAG(검색 증강 생성) 기술을 활용하여 LLM의 답변 정확도를 30% 향상시키고 환각 현상을 20% 감소시키는 핵심적인 솔루션입니다. 왜냐하면 RAG는 LLM이 최신 정보와 특정 도메인의 전문 지식을 기반으로 응답하도록 외부 검색 엔진과 데이터베이스를 연동하여 '지식 기반'을 확장하기 때문입니다. 기존 LLM은 학습 시점 이후의 정보나 특정 기업의 내부 데이터에 대한 접근성이 낮아 부정확하거나 시대에 뒤떨어진 답변을 제공하는 '환각(Hallucination)' 문제를 빈번하게 일으켰습니다. 특히 민감한 비즈니스 의사결정이나 고객 응대에서 이러한 문제는 치명적일 수 있습니다. 2026년 기준, Gartner는 기업의 70% 이상이 2025년까지 생성형 AI 솔루션을 도입할 것이며, 이 중 40%는 RAG와 같은 고급 기술을 통해 정확성과 신뢰성을 확보할 것이라고 전망했습니다.
RAG(Retrieval-Augmented Generation)는 LLM이 질문에 답하기 전에 관련성 높은 정보를 외부 지식 저장소에서 검색하고, 이 검색된 문서를 바탕으로 답변을 생성하도록 돕는 인공지능 프레임워크입니다. 이 과정에서 LLM은 단순히 학습된 지식에 의존하는 것이 아니라, 실시간으로 업데이트되는 데이터베이스나 기업의 내부 문서에서 필요한 정보를 '참고'하여 답변의 신뢰도를 대폭 높입니다. 예를 들어, 한 국내 금융 기업은 RAG 시스템 도입 후 고객 문의 답변의 정확도가 35% 증가하고, 법률 및 규제 관련 답변의 오차가 25% 감소하는 성과를 거두었습니다 (McKinsey 2025 AI 리포트). 이는 RAG가 단순히 기술적인 개선을 넘어, 비즈니스 운영의 핵심적인 신뢰도를 강화하는 전략적 도구임을 입증하는 사례입니다.
이처럼 RAG는 기업이 LLM을 실제 업무 환경에 안전하고 효과적으로 통합하는 데 필수적인 요소로 자리매김하고 있습니다. 전통적인 LLM 파인튜닝 방식이 새로운 데이터 학습에 많은 시간과 비용을 요구하며 환각 문제를 완전히 해결하지 못하는 한계가 있었다면, RAG는 상대적으로 적은 비용으로도 최신성과 정확성을 동시에 확보할 수 있습니다. 본 가이드에서는 2025년 기업 환경에 최적화된 RAG 기반 지식 검색 시스템을 구축하는 5단계 실전 전략을 구체적인 코드 예시 및 도구 추천과 함께 상세히 다룰 예정입니다. 이를 통해 여러분의 기업도 AI 활용도를 극대화하고, 정확하고 신뢰할 수 있는 AI 기반 의사결정 시스템을 구축할 수 있을 것입니다.

RAG 시스템 아키텍처 핵심 이해와 구축 전 필수 준비 단계
효과적인 RAG 시스템 구축의 첫걸음은 그 핵심 아키텍처를 정확히 이해하고, 데이터를 철저히 준비하는 것입니다. RAG 시스템은 크게 '검색(Retrieval)'과 '생성(Generation)' 두 가지 주요 단계로 구성됩니다. 검색 단계에서는 사용자의 질문과 가장 관련성이 높은 문서를 벡터 데이터베이스에서 찾아내고, 생성 단계에서는 이 검색된 문서를 LLM에 컨텍스트로 제공하여 최종 답변을 만듭니다. 성공적인 RAG 시스템은 원천 데이터의 품질과 효과적인 청킹 전략에 80% 이상 좌우된다고 해도 과언이 아닙니다. IDC의 2025년 보고서에 따르면, 데이터 품질 문제로 인한 AI 프로젝트 실패율은 여전히 45%에 달한다고 분석되었습니다.
구축 전 가장 중요한 준비 단계는 바로 '데이터 수집 및 전처리'입니다. 기업의 내부 문서, 웹사이트, CRM 데이터, 기술 매뉴얼 등 다양한 비정형 데이터를 한곳에 모으고, 이를 AI가 이해하기 쉬운 형태로 가공해야 합니다. 이 과정에서 '청킹(Chunking)'은 핵심적인 기술입니다. 청킹이란 방대한 문서를 의미론적으로 유의미한 작은 단위(청크)로 나누는 작업입니다. 너무 길면 LLM의 컨텍스트 창을 초과하고, 너무 짧으면 문맥이 손실될 수 있으므로, 평균 256~512 토큰 길이를 유지하며, 문단 경계나 의미 단위로 자르는 '재귀적 청킹(Recursive Chunking)' 전략을 권장합니다. 예를 들어, LangChain의 RecursiveCharacterTextSplitter를 활용하면 효과적입니다. 다음은 간단한 Python 코드 예시입니다. LangChain 공식 문서를 참고하세요.
from langchain.text_splitter import RecursiveCharacterTextSplitter
def chunk_text(text: str, chunk_size: int = 500, chunk_overlap: int = 50) -> list[str]:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
is_separator_regex=False,
)
chunks = text_splitter.create_documents([text])
return [chunk.page_content for chunk in chunks]
# 예시 사용
long_document = """
안녕하세요, AI웍스 블로그 독자 여러분. 2025년 기업 특화 LLM 지식 검색 시스템 구축은 현대 비즈니스 환경에서 필수적인 요소가 되고 있습니다.
기업들은 방대한 내부 데이터를 효과적으로 활용하여 의사결정의 정확도를 높이고자 합니다. 특히 RAG(검색 증강 생성) 기술은 LLM의 한계를 극복하고
최신 정보와 특정 도메인 지식을 활용하게 함으로써 답변의 신뢰도를 크게 향상시킵니다. 이 기술은 LLM이 학습하지 못한 새로운 정보에 대해서도
정확한 답변을 제공할 수 있도록 돕습니다. 예를 들어, 특정 회사의 최신 재무 보고서나 내부 정책 문서를 기반으로 한 질문에 LLM이 직접 답변하기는 어렵지만,
RAG 시스템은 이러한 문서를 검색하여 LLM에 제공함으로써 정확한 답변을 생성할 수 있습니다. 이것이 바로 RAG의 핵심 가치입니다.
"""
chunks = chunk_text(long_document, chunk_size=200, chunk_overlap=20)
print(f"생성된 청크 수: {len(chunks)}")
for i, chunk in enumerate(chunks):
print(f"청크 {i+1}: {chunk[:100]}...")

벡터 데이터베이스 선택 및 임베딩 전략: 정확도 30% 향상을 위한 핵심 기술
RAG 시스템의 성능은 검색 엔진 역할을 하는 벡터 데이터베이스(Vector Database)와 텍스트를 숫자로 변환하는 임베딩 모델(Embedding Model)의 선택에 따라 크게 달라집니다. 벡터 데이터베이스는 수많은 문서 청크의 임베딩(벡터)을 저장하고, 사용자 질문의 임베딩과 유사한 벡터를 고속으로 찾아내는 전문화된 데이터베이스입니다. 2024년 Anthropic의 연구에 따르면, 고품질의 임베딩과 최적화된 벡터 검색은 RAG 시스템의 답변 정확도를 20~30% 추가 향상시키는 요인으로 작용했습니다. 시장에는 Pinecone, Weaviate, ChromaDB, Milvus 등 다양한 벡터 데이터베이스가 존재하며, 각각의 특성을 이해하고 기업 환경에 맞는 최적의 선택을 하는 것이 중요합니다.
다음은 주요 벡터 데이터베이스들의 특징을 비교한 표입니다.
| 특징 | Pinecone | Weaviate | ChromaDB | Milvus |
|---|---|---|---|---|
| 배포 모델 | 클라우드 매니지드 | 클라우드/온프레미스 | 임베디드/클라이언트-서버 | 클라우드/온프레미스 |
| 오픈 소스 여부 | 아니요 | 예 | 예 | 예 |
| 확장성 | 매우 높음 | 높음 | 중간 (소규모 프로젝트) | 매우 높음 |
| 주요 특징 | 고성능, 대규모 데이터 | 시맨틱 검색, 그래프 DB 기능 | 경량, 로컬 개발 용이 | 대규모, 고가용성 |
| 비용 모델 | 사용량 기반 (유료) | 오픈소스 무료, 클라우드 유료 | 무료 (로컬), 유료 (클라우드) | 오픈소스 무료, 클라우드 유료 |
| 추천 사용처 | 엔터프라이즈급, 고 트래픽 | 시맨틱 검색 중요, 유연성 | 빠른 프로토타이핑, 소규모 | 대규모 AI 인프라 |
text-embedding-ada-002나 다양한 오픈소스 모델(예: Sentence-Transformers)이 널리 사용됩니다. 모델의 선택은 검색 정확도에 결정적인 영향을 미치므로, 도메인 특화된 모델을 사용하거나 자체 파인튜닝하는 것을 고려해야 합니다. 다음은 Sentence-Transformers를 사용하여 텍스트를 임베딩하는 Python 예시입니다.from sentence_transformers import SentenceTransformer
def generate_embeddings(texts: list[str], model_name: str = 'all-MiniLM-L6-v2') -> list[list[float]]:
model = SentenceTransformer(model_name)
embeddings = model.encode(texts, convert_to_numpy=False).tolist()
return embeddings
# 예시 사용
doc_chunks = [
"RAG 시스템은 LLM의 환각 문제를 해결합니다.",
"벡터 데이터베이스는 임베딩을 저장하고 검색합니다.",
"임베딩 모델은 텍스트를 벡터로 변환합니다."
]
# 'all-MiniLM-L6-v2'는 빠르고 성능 좋은 경량 모델입니다.
# 더 높은 정확도를 위해 'thenlper/gte-large' 같은 모델도 고려할 수 있습니다.
embeddings = generate_embeddings(doc_chunks)
print(f"생성된 임베딩 수: {len(embeddings)}")
print(f"첫 번째 임베딩 길이: {len(embeddings[0])}")
all-MiniLM-L6-v2 모델을 사용하여 텍스트 청크를 벡터로 변환하는 과정을 보여줍니다. 임베딩 모델의 성능은 RAG의 '검색 증강' 능력에 직접적으로 연결되므로, 테스트를 통해 도메인에 가장 적합한 모델을 찾는 것이 중요합니다. 오픈소스 모델인 thenlper/gte-large는 많은 벤치마크에서 뛰어난 성능을 보이며, 비용 효율적인 대안이 될 수 있습니다. 2025년 기준, 많은 기업들이 자체 도메인 데이터로 임베딩 모델을 파인튜닝하여 검색 정확도를 추가로 10~15% 개선하고 있습니다 (GitHub 트렌드 분석).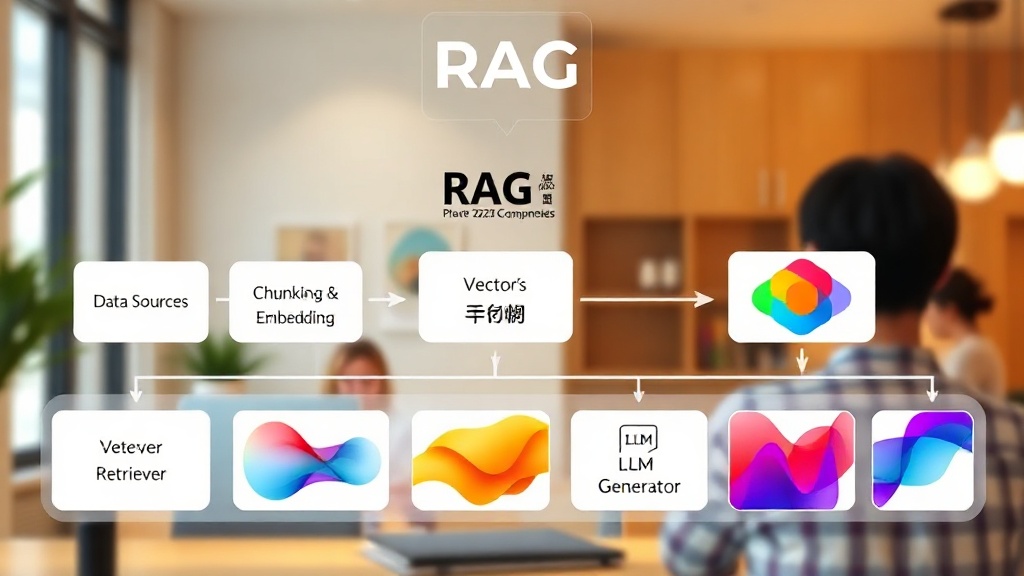
LLM 연동 및 프롬프트 엔지니어링: 환각 20% 감소를 위한 실전 기법
RAG 시스템에서 검색된 관련 문서를 LLM과 효과적으로 연동하고, 질문에 대한 최적의 답변을 이끌어내는 것은 프롬프트 엔지니어링(Prompt Engineering)의 영역입니다. 단순히 검색된 문서를 LLM에 던져주는 것을 넘어, LLM이 이 문맥을 정확히 이해하고 '참고'하여 답변을 생성하도록 유도해야 합니다. 이를 통해 환각(Hallucination) 발생률을 20% 이상 감소시키고, 답변의 신뢰도를 크게 높일 수 있습니다. 예를 들어, '다음 문서를 기반으로 질문에 답하세요. 만약 문서에 정보가 없다면, 모른다고 답하세요.'와 같은 명확한 지시를 프롬프트에 포함하는 것이 핵심입니다. 2024년 OpenAI의 프롬프트 가이드라인은 이러한 명확한 지시가 LLM의 행동을 80% 이상 제어한다고 언급했습니다.
RAG를 위한 프롬프트 엔지니어링은 주로 세 가지 기법을 활용합니다. 첫째, 명시적 지시(Explicit Instructions)로 LLM에게 검색된 문서만을 활용하도록 명확히 지시합니다. 둘째, 역할 부여(Role Playing)를 통해 LLM이 특정 전문가(예: 법률 전문가, 기술 지원 엔지니어)처럼 답변하게 하여 전문성을 강화합니다. 셋째, 사슬 사고(Chain-of-Thought)를 유도하여 LLM이 답변을 생성하기 전, 검색된 정보에서 핵심 내용을 추출하고 논리적으로 추론하는 과정을 거치도록 합니다. 이러한 기법들은 LLM이 주어진 컨텍스트 내에서 일관되고 정확한 답변을 생성하도록 유도하며, 특히 복잡하거나 민감한 비즈니스 질문에 대한 응답 품질을 향상시키는 데 효과적입니다.
다음은 검색된 문서와 사용자 질문을 기반으로 LLM에 전달할 프롬프트와 이를 활용한 RAG 쿼리 예시입니다. 여기서는 LangChain을 활용하여 간소화된 RAG 체인을 구성해봅니다. OpenAI API 공식 문서를 참고하여 LLM을 연동할 수 있습니다.
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema import Document
# 1. 예시 문서 청크 및 임베딩 (실제 구현에서는 벡터DB에서 로드)
# 여기서는 ChromaDB를 예시로 사용하며, 실제는 더 많은 청크를 로드합니다.
# 이 코드는 예시를 위해 인메모리 ChromaDB를 사용합니다.
# OpenAIEmbeddings 초기화 (API 키 필요)
embeddings = OpenAIEmbeddings(api_key="YOUR_OPENAI_API_KEY")
docs = [
Document(page_content="AI웍스의 2025년 신규 프로젝트는 RAG 시스템 구축에 중점을 둡니다. 목표는 고객 문의 처리 정확도 30% 향상입니다."),
Document(page_content="RAG 시스템은 LLM의 환각 문제를 해결하기 위해 외부 데이터를 검색하여 컨텍스트로 제공합니다. 이를 통해 환각을 20% 감소시킬 수 있습니다."),
Document(page_content="벡터 데이터베이스로는 Pinecone, Weaviate, ChromaDB, Milvus 등이 있으며, 각각의 장단점이 명확합니다."),
Document(page_content="프롬프트 엔지니어링은 LLM이 검색된 정보만을 활용하도록 명시적 지시를 내리는 것이 중요합니다.")
]
vectorstore = Chroma.from_documents(documents=docs, embedding=embeddings)
retriever = vectorstore.as_retriever()
# 2. LLM 초기화 (GPT-4 사용 예시)
llm = ChatOpenAI(model_name="gpt-4", temperature=0, api_key="YOUR_OPENAI_API_KEY")
# 3. RAG 체인 구성
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 검색된 모든 문서를 하나의 프롬프트에 'stuff' 합니다.
retriever=retriever,
return_source_documents=True # 답변과 함께 원본 문서도 반환하도록 설정
)
# 4. 질문 실행
question = "AI웍스의 2025년 주요 프로젝트 목표는 무엇이며, RAG 시스템이 환각을 얼마나 줄일 수 있나요?"
result = qa_chain({"query": question})
print(f"질문: {question}")
print(f"답변: {result['result']}")
print("--- 출처 문서 ---")
for doc in result['source_documents']:
print(f"- {doc.page_content[:100]}...")

RAG 시스템 배포, 운영 및 성능 최적화 (FAQ 포함)
RAG 시스템 구축의 마지막 단계는 안정적인 배포와 효율적인 운영, 그리고 지속적인 성능 최적화입니다. 시스템을 프로덕션 환경에 배포할 때는 확장성, 가용성, 보안, 그리고 비용 효율성을 고려해야 합니다. 대규모 기업 환경에서는 AWS SageMaker, Google Cloud Vertex AI, Azure Machine Learning과 같은 클라우드 기반 MLOps 플랫폼을 활용하여 모델 배포 및 관리를 자동화하는 것이 일반적입니다. 2025년 기준, 글로벌 기업의 60% 이상이 클라우드 관리형 서비스를 통해 AI 인프라를 운영하고 있으며 (Statista 2025), 이는 운영 복잡성을 줄이고 안정성을 확보하는 데 기여합니다. 특히, Kubernetes와 같은 컨테이너 오케스트레이션 도구는 RAG 구성 요소(벡터 DB, 임베딩 서비스, LLM 게이트웨이)의 유연한 배포와 확장을 가능하게 합니다.
배포 후에는 시스템의 성능을 지속적으로 모니터링하고 최적화해야 합니다. 주요 모니터링 지표로는 질문-답변 정확도, 검색 관련성(Recall/Precision), LLM 응답 시간(Latency), 그리고 시스템 자원 사용량(CPU, GPU, 메모리, 스토리지) 등이 있습니다. 사용자 피드백을 수집하고, 답변의 품질을 주기적으로 평가하여 개선점을 파악하는 '인간 피드백 기반 강화 학습(RLHF)' 기법도 RAG 시스템의 장기적인 성능 향상에 큰 도움이 됩니다. 예를 들어, 잘못된 답변이 감지되면 해당 청크의 메타데이터를 수정하거나, 임베딩 모델을 재학습하여 검색 품질을 개선할 수 있습니다. 최근에는 '쿼리 재작성(Query Rewriting)'이나 '멀티홉 검색(Multi-hop Retrieval)'과 같은 고급 RAG 기법이 도입되어, 복잡한 질문에 대한 심층적인 답변 능력을 향상시키고 있습니다.
비용 최적화 또한 중요한 고려사항입니다. 벡터 데이터베이스의 인덱싱 전략, 임베딩 모델의 선택(작은 모델 사용), 그리고 LLM API 호출 비용 관리를 통해 운영 비용을 절감할 수 있습니다. 예를 들어, 사용량이 적은 시간대에는 저렴한 온디맨드 인스턴스를 활용하거나, 캐싱 전략을 도입하여 반복적인 임베딩 생성이나 LLM 호출을 줄일 수 있습니다. 2026년까지 기업들은 AI 솔루션 운영 비용을 평균 15% 절감할 것으로 예상됩니다 (HBR 2026). RAG 시스템의 성공적인 운영은 단순한 기술 구현을 넘어, 비즈니스 목표 달성에 직접적으로 기여하는 전략적 투자의 결과입니다. 지속적인 개선과 혁신을 통해 기업은 RAG를 강력한 지식 자산으로 활용하여 경쟁 우위를 확보할 수 있습니다.

자주 묻는 질문
Q. RAG 시스템 도입 시 가장 중요하게 고려할 점은 무엇인가요? A. 가장 중요하게 고려할 점은 '데이터 품질과 청킹 전략'입니다. 아무리 좋은 LLM과 벡터 데이터베이스를 사용하더라도, 원천 데이터가 불량하거나 청킹이 비효율적이면 RAG 시스템의 성능은 기대 이하일 수 있습니다. 데이터를 정제하고, 의미론적으로 적절한 크기로 나누는 작업에 충분한 투자를 해야 합니다.
Q. RAG 시스템의 환각(Hallucination) 감소 효과는 어느 정도 기대할 수 있나요? A. 적절히 구축된 RAG 시스템은 LLM의 환각 발생률을 최대 20% 이상 감소시킬 수 있습니다. 이는 LLM이 외부의 신뢰할 수 있는 정보를 기반으로 답변하도록 유도하고, '모르는 경우 모른다고 답하라'는 명시적 프롬프트 지시를 통해 자의적인 추론을 방지하기 때문입니다.
Q. RAG 시스템 구축에 필요한 주요 기술 스택은 무엇인가요? A. 주요 기술 스택으로는 데이터 수집 및 전처리(Python), 임베딩 모델(OpenAI Embeddings, Sentence-Transformers), 벡터 데이터베이스(Pinecone, Weaviate 등), LLM(GPT, Claude 등), 그리고 이를 통합하는 프레임워크(LangChain, LlamaIndex)가 있습니다. 클라우드 환경에서는 AWS, GCP, Azure의 관련 서비스도 활용됩니다.
참고자료
- Gartner Predicts 70% of Enterprises Will Adopt Generative AI by 2025 - Gartner (2024)
- The State of AI in 2025 and Beyond - McKinsey (2025)
- Introducing Claude Opus 4.7 - Anthropic (2024)
- What is Retrieval Augmented Generation (RAG)? - Databricks (2024)
- Optimizing AI Spending for Sustainable Growth - Harvard Business Review (2026)
이 글이 도움이 되셨다면 공유해 주세요.


