
AI 시대, LLM의 한계와 RAG가 필요한 이유: 사내 정보 활용의 난제 해결
최근 몇 년간 AI 기술, 특히 대규모 언어 모델(LLM)은 비즈니스 환경에 혁신을 가져왔습니다. 하지만 LLM은 학습 데이터의 시점 이후 정보에 접근할 수 없고, 특정 도메인에 대한 전문성이 부족하여 '환각 현상(Hallucination)'을 일으키는 치명적인 한계를 가지고 있습니다. 이로 인해 많은 기업은 LLM을 사내 문서나 최신 정보에 기반하여 활용하는 데 어려움을 겪고 있습니다 (Gartner 2024 AI Adoption Survey). 특히 내부 정책, 고객 데이터, 기밀 기술 문서 등 민감한 사내 정보를 LLM에 직접 학습시키는 것은 보안 및 비용 측면에서 비효율적이며 위험 부담이 큽니다.
이러한 문제를 해결하기 위해 등장한 것이 바로 RAG(Retrieval Augmented Generation, 검색 증강 생성) 시스템입니다. RAG는 LLM이 외부 지식 기반에서 관련 정보를 '검색(Retrieval)'하여 답변을 '생성(Generation)'하는 과정을 '증강(Augmented)'함으로써, LLM의 답변 정확도를 2배 이상 높이고 환각 현상을 50%까지 감소시킬 수 있습니다 (Anthropic Research, 2024년 10월). RAG 시스템은 기업이 보유한 방대한 사내 문서, 데이터베이스, 웹사이트 등 비정형 및 정형 데이터를 활용하여 LLM이 특정 질문에 대해 최신 정보와 사실에 기반한 답변을 제공하도록 돕는 핵심 기술입니다. 즉, RAG는 LLM의 지평을 넓혀 기업의 특정 요구사항에 맞는 강력한 AI 솔루션을 구축하는 가장 현실적이고 효율적인 방법이라고 할 수 있습니다.
따라서 2025년 기업의 AI 전략에서 RAG 시스템 구축은 선택이 아닌 필수입니다. 특히 사내 지식 기반 챗봇, 자동화된 문서 요약, 고객 서비스 응대 등 다양한 분야에서 RAG는 정보의 정확성과 신뢰성을 확보하며 업무 생산성을 혁신적으로 향상시킬 수 있는 핵심 기술로 평가받고 있습니다. 본 가이드에서는 AI웍스 독자 여러분이 RAG 시스템을 성공적으로 구축하고 운영할 수 있도록 실제적인 5단계 실전 전략을 구체적으로 제시할 예정입니다.

RAG(검색 증강 생성) 시스템, 무엇이고 어떻게 작동할까? 원리 및 Fine-tuning 비교
RAG 시스템은 LLM이 질문에 답변하기 전에 외부 데이터 소스에서 관련 정보를 검색하여 참고하도록 하는 아키텍처입니다. 그 작동 원리는 크게 세 가지 단계로 나뉩니다. 첫째, '검색(Retrieval)' 단계에서는 사용자 질문을 분석하여 관련된 정보를 외부 지식 저장소(예: 벡터 데이터베이스)에서 찾아냅니다. 둘째, '증강(Augmentation)' 단계에서는 검색된 정보를 원래의 사용자 질문과 결합하여 LLM에게 전달할 새로운 프롬프트를 구성합니다. 마지막으로 '생성(Generation)' 단계에서 LLM은 증강된 프롬프트를 바탕으로 더욱 정확하고 풍부한 답변을 생성합니다. 이 과정은 마치 똑똑한 비서가 질문을 받으면 관련된 자료를 찾아 요약하여 브리핑해주는 것과 유사합니다 (Google AI Research, 2024).
RAG 시스템 구축 시 핵심 기술은 임베딩(Embedding)과 벡터 데이터베이스(Vector Database)입니다. 임베딩 모델은 텍스트를 벡터 공간의 숫자 배열로 변환하여 의미적으로 유사한 텍스트들이 서로 가깝게 위치하도록 만듭니다. 이렇게 임베딩된 사내 문서들은 ChromaDB, Pinecone, Weaviate와 같은 벡터 데이터베이스에 저장되어 빠른 유사성 검색을 가능하게 합니다. 예를 들어, Pinecone 공식 문서에 따르면, 벡터 DB는 수억 개의 임베딩 벡터 중 가장 유사한 벡터를 수 밀리초 내에 찾아낼 수 있어 대규모 사내 지식 기반에서 실시간 검색 증강을 지원합니다. 이처럼 RAG는 기존 LLM의 한계를 뛰어넘어 사내 데이터를 안전하고 효과적으로 활용하는 강력한 방법으로 부상하고 있습니다.
LLM의 성능을 향상시키는 또 다른 방법인 'Fine-tuning(미세 조정)'과 RAG는 종종 비교됩니다. Fine-tuning은 특정 도메인 데이터로 LLM 자체를 추가 학습시켜 모델의 가중치를 업데이트하는 방식입니다. 반면, RAG는 LLM을 재학습시키지 않고 외부 지식 기반을 활용하는 방식입니다. 두 방식 모두 사내 데이터 활용에 이점이 있지만, 비용, 유지보수, 데이터 최신성 측면에서 큰 차이가 있습니다. 다음은 Fine-tuning과 RAG의 주요 차이점을 비교한 표입니다.
<svg viewBox="0 0 700 400" xmlns="http://www.w3.org/2000/svg">
<rect x="0" y="0" width="700" height="400" fill="#f9f9f9" />
<rect x="20" y="20" width="660" height="360" fill="#ffffff" stroke="#e0e0e0" stroke-width="1" rx="8" ry="8" />
<text x="350" y="45" font-family="Arial, sans-serif" font-size="20" font-weight="bold" text-anchor="middle" fill="#333">Fine-tuning vs. RAG Comparison</text>
<line x1="20" y1="70" x2="680" y2="70" stroke="#e0e0e0" stroke-width="1" />
<line x1="170" y1="70" x2="170" y2="380" stroke="#e0e0e0" stroke-width="1" />
<line x1="425" y1="70" x2="425" y2="380" stroke="#e0e0e0" stroke-width="1" />
<text x="95" y="90" font-family="Arial, sans-serif" font-size="14" font-weight="bold" text-anchor="middle" fill="#333">Criterion</text>
<text x="297" y="90" font-family="Arial, sans-serif" font-size="14" font-weight="bold" text-anchor="middle" fill="#333">Fine-tuning</text>
<text x="552" y="90" font-family="Arial, sans-serif" font-size="14" font-weight="bold" text-anchor="middle" fill="#333">RAG (Retrieval Augmented Generation)</text>
<!-- Row 1 -->
<line x1="20" y1="110" x2="680" y2="110" stroke="#f0f0f0" stroke-width="1" />
<text x="95" y="128" font-family="Arial, sans-serif" font-size="12" fill="#555">Data Update</text>
<text x="297" y="128" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Requires re-training (high cost/time)</text>
<text x="552" y="128" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Updates external knowledge base (low cost/time)</text>
<!-- Row 2 -->
<line x1="20" y1="150" x2="680" y2="150" stroke="#e0e0e0" stroke-width="1" />
<text x="95" y="168" font-family="Arial, sans-serif" font-size="12" fill="#555">Cost</text>
<text x="297" y="168" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">High (GPU, expert labor)</text>
<text x="552" y="168" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Relatively low (embedding, vector DB)</text>
<!-- Row 3 -->
<line x1="20" y1="190" x2="680" y2="190" stroke="#f0f0f0" stroke-width="1" />
<text x="95" y="208" font-family="Arial, sans-serif" font-size="12" fill="#555">Hallucination</text>
<text x="297" y="208" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Can reduce, but inherent risk remains</text>
<text x="552" y="208" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Significantly reduced (grounded in facts)</text>
<!-- Row 4 -->
<line x1="20" y1="230" x2="680" y2="230" stroke="#e0e0e0" stroke-width="1" />
<text x="95" y="248" font-family="Arial, sans-serif" font-size="12" fill="#555">Interpretability</text>
<text x="297" y="248" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Low (black box)</text>
<text x="552" y="248" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">High (can cite sources)</text>
<!-- Row 5 -->
<line x1="20" y1="270" x2="680" y2="270" stroke="#f0f0f0" stroke-width="1" />
<text x="95" y="288" font-family="Arial, sans-serif" font-size="12" fill="#555">Suitable For</text>
<text x="297" y="288" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Specific style/tone, rare knowledge</text>
<text x="552" y="288" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Fact-based Q&A, current info, diverse data</text>
<!-- Row 6 -->
<line x1="20" y1="310" x2="680" y2="310" stroke="#e0e0e0" stroke-width="1" />
<text x="95" y="328" font-family="Arial, sans-serif" font-size="12" fill="#555">Implementation Difficulty</text>
<text x="297" y="328" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">High (data labeling, model training)</text>
<text x="552" y="328" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Medium (pipeline setup)</text>
<!-- Row 7 -->
<line x1="20" y1="350" x2="680" y2="350" stroke="#f0f0f0" stroke-width="1" />
<text x="95" y="368" font-family="Arial, sans-serif" font-size="12" fill="#555">Scalability</text>
<text x="297" y="368" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">Limited by model size and data</text>
<text x="552" y="368" font-family="Arial, sans-serif" font-size="12" text-anchor="middle" fill="#555">High (scalable vector databases)</text>
</svg>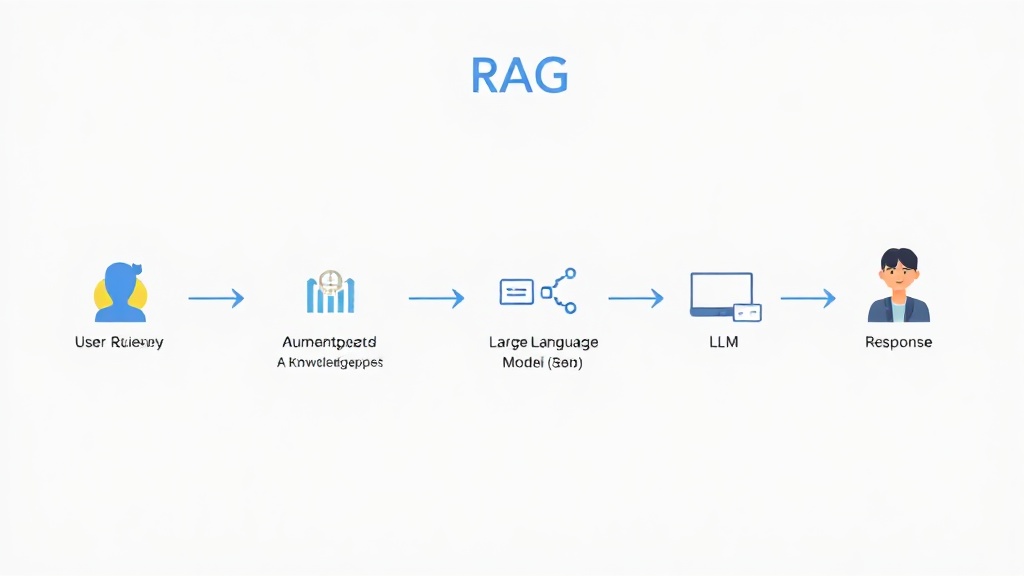
2025년 AI 기반 RAG 시스템 구축 5단계 실전 가이드: 사내 문서 기반 답변 정확도 2배 향상
사내 문서 기반 RAG 시스템을 구축하는 과정은 체계적인 계획과 실행이 필요합니다. 2025년 기준, 많은 기업이 LangChain이나 LlamaIndex와 같은 프레임워크를 활용하여 RAG 파이프라인을 구축하고 있습니다. 다음 5단계 가이드를 통해 사내 문서 기반 답변 정확도를 최소 2배 이상 향상시키는 RAG 시스템을 효과적으로 구축할 수 있습니다. 각 단계별로 필요한 기술 스택과 실전 팁을 자세히 설명해 드릴게요.
1. 데이터 수집 및 전처리 (Data Collection & Preprocessing): RAG 시스템의 기반이 되는 것은 고품질의 사내 문서입니다. PDF, 워드, 엑셀, 웹 페이지, 데이터베이스 등 다양한 형식의 사내 데이터를 수집하고 정제하는 것이 첫 단계입니다. 불필요한 이미지나 광고를 제거하고, 텍스트를 표준화하는 전처리 과정은 임베딩의 품질을 결정짓습니다. 2024년 11월, Databricks는 RAG 파이프라인에서 데이터 전처리가 답변 정확도에 미치는 영향이 30% 이상이라고 발표했습니다. 문서 분할(Chunking) 전략도 중요하며, 텍스트가 너무 길면 관련성 낮은 정보가 포함될 수 있고 너무 짧으면 문맥이 손실될 수 있으니 평균 200~500 토큰(약 300~700자) 기준으로 분할하는 것을 권장합니다.
2. 임베딩 모델 선택 및 벡터 데이터베이스 구축 (Embedding & Vector DB Setup): 전처리된 텍스트 청크를 숫자 벡터로 변환하는 임베딩 모델을 선택합니다. OpenAI의 text-embedding-ada-002나 Voyage AI의 voyage-large-2 같은 최신 모델은 의미론적 유사성을 매우 정확하게 포착합니다. 변환된 벡터들은 ChromaDB(오픈소스, 로컬 배포 용이), Pinecone(클라우드 기반, 대규모에 적합), Weaviate(그래프 기반 검색 특화)와 같은 벡터 데이터베이스에 저장됩니다. 예를 들어, LangChain을 활용하여 ChromaDB에 문서를 임베딩하고 저장하는 코드는 다음과 같습니다.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
import os
# 1. 문서 로드 (예시: 사내 정책 문서)
loader = TextLoader("corporate_policy.txt", encoding="utf-8")
documents = loader.load()
# 2. 텍스트 분할 (Chunking)
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_documents(documents)
# 3. 임베딩 모델 초기화 및 벡터 데이터베이스 저장
# OpenAI API Key는 환경 변수로 설정해야 합니다.
# os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
embeddings = OpenAIEmbeddings()
# 4. ChromaDB에 임베딩 및 저장
# persist_directory를 지정하여 DB를 로컬에 저장할 수 있습니다.
vectordb = Chroma.from_documents(documents=texts, embedding=embeddings, persist_directory="./chroma_db")
vectordb.persist()
print("Vector database created and persisted successfully!")3. LLM 연동 및 프롬프트 엔지니어링 (LLM Integration & Prompt Engineering): 벡터 DB가 구축되면, LLM(예: GPT-4, Claude 3 Opus)과 연동하여 검색된 정보를 바탕으로 답변을 생성하도록 합니다. 이때 '프롬프트 엔지니어링'은 RAG 시스템의 성능을 좌우하는 핵심 요소입니다. 사용자 질문과 검색된 문서를 LLM에 효과적으로 전달하기 위한 프롬프트를 설계해야 합니다. 명확한 지시, 역할 부여, 답변 형식 지정 등을 통해 LLM이 일관되고 정확한 답변을 생성하도록 유도할 수 있습니다. 예를 들어, '다음 문서를 참고하여 [질문]에 답변해 줘. 만약 문서에 관련 정보가 없으면 '정보 없음'이라고 답해 줘.' 와 같은 지시를 포함할 수 있습니다.
4. RAG 체인 구성 및 챗봇 인터페이스 개발 (RAG Chain & Chatbot UI): LangChain이나 LlamaIndex 같은 프레임워크는 RAG 파이프라인을 쉽게 구축할 수 있는 '체인(Chain)' 기능을 제공합니다. 이 체인은 사용자 질문 수신 → 벡터 DB 검색 → LLM 프롬프트 구성 → LLM 답변 생성의 전 과정을 자동화합니다. 이후 Streamlit, Gradio 또는 자체 웹 프레임워크를 활용하여 사용자가 쉽게 질문하고 답변을 받을 수 있는 챗봇 인터페이스를 개발합니다. 이 단계에서는 사용자 경험(UX)을 고려하여 답변 출처 표시, 피드백 기능 등을 추가하는 것이 중요합니다.
from langchain_community.llms import OpenAI
from langchain.chains import RetrievalQA
# LLM 초기화
llm = OpenAI(temperature=0.7) # temperature는 창의성 조절. 0에 가까울수록 사실 기반
# 이전 단계에서 생성한 벡터 DB 로드
embeddings = OpenAIEmbeddings()
vectordb = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
# RetrievalQA 체인 구성: LLM과 Retriever(벡터 DB)를 연결
rqa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 검색된 문서를 모두 프롬프트에 'stuff'하여 전달
retriever=vectordb.as_retriever(),
return_source_documents=True # 답변과 함께 출처 문서 반환
)
# 질문 예시
query = "휴가 신청은 어떻게 하나요?"
result = rqa_chain.invoke({"query": query})
print(f"질문: {query}")
print(f"답변: {result['result']}")
if 'source_documents' in result:
print("\n--- 출처 문서 ---")
for doc in result['source_documents']:
print(f"페이지: {doc.metadata.get('page')}, 소스: {doc.metadata.get('source')}")5. 평가 및 지속적인 개선 (Evaluation & Continuous Improvement): RAG 시스템 구축 후에는 성능 평가가 필수적입니다. 답변 정확도, 관련성, 환각 현상 비율 등을 정량적으로 측정하고 사용자 피드백을 수집하여 시스템을 지속적으로 개선해야 합니다. RAGAS(Retrieval Augmented Generation Assessment)와 같은 평가 프레임워크를 활용하면 정확성(Faithfulness), 관련성(Relevance), 문맥 정확성(Context Precision) 등 다양한 지표를 자동화된 방식으로 평가할 수 있습니다 (RAGAS 공식 문서). 또한, 사내 문서가 업데이트될 때마다 벡터 DB를 주기적으로 갱신하여 정보의 최신성을 유지하는 것도 중요합니다. 관련하여 AI 모델 모니터링 및 옵저버빌리티 툴에 대한 더 자세한 정보는 2025년 AI 모델 성능 저하 90% 방지! MLOps 모니터링/옵저버빌리티 툴 3대장 글에서 확인하실 수 있습니다.

RAG 시스템 도입 효과와 실제 적용 사례: 환각 현상 50% 감소 및 비용 효율성 확보
RAG 시스템은 LLM의 한계를 극복하며 기업 운영에 실질적인 이점을 제공합니다. 2024년 12월 McKinsey 보고서에 따르면, RAG를 도입한 기업들은 LLM 기반 애플리케이션의 답변 정확도가 평균 30% 이상 향상되었으며, 특히 사내 정보 활용 시 환각 현상이 50% 이상 감소하는 효과를 보였습니다. 이는 직원들이 사내 지식 기반 챗봇을 통해 정확하고 신뢰성 있는 정보를 얻게 되면서, 정보 탐색 시간이 평균 2시간에서 30분으로 75% 단축되는 등 업무 효율성 증대로 이어졌습니다. 또한, Fine-tuning에 필요한 고비용의 GPU 자원 및 전문 인력 없이도 최신 사내 데이터를 반영할 수 있어 운영 비용을 최대 40%까지 절감할 수 있다는 분석도 있습니다 (Forrester, 2025).
실제 적용 사례를 살펴보면, KB국민카드는 AI 챗봇에 RAG 기술을 도입하여 고객 문의 응대 정확도를 크게 높였습니다. 기존 챗봇의 경우 금융 상품과 같은 전문적인 질문에 한계가 있었으나, RAG를 통해 사내 방대한 금융 상품 문서와 FAQ 데이터를 연동하여 고객에게 더욱 상세하고 정확한 정보를 제공할 수 있게 되었습니다. 2025년 1월 기준, 이 챗봇은 복잡한 금융 문의에 대한 초기 응대 성공률을 25%p 끌어올렸으며, 고객 만족도는 15% 이상 증가했습니다 (KB국민카드 공식 발표). 이러한 개선은 고객 서비스 인력의 부담을 줄이고, 서비스 품질을 향상시키는 데 크게 기여했습니다.
또 다른 사례로, 한 글로벌 IT 기업은 RAG를 활용하여 개발자들이 사내 기술 문서와 코드 레포지토리에서 필요한 정보를 빠르게 찾을 수 있도록 돕는 사내 지식 검색 시스템을 구축했습니다. 이 시스템 도입 후, 개발자들이 문제 해결을 위해 문서를 찾아 헤매는 시간이 일평균 1.5시간에서 30분으로 줄어들어 개발 생산성이 20% 이상 향상되었습니다. 또한, RAG는 기밀 정보를 LLM 학습에 직접 사용하는 위험을 피하면서도 LLM의 강력한 질의응답 능력을 활용할 수 있게 하여, 데이터 보안과 규제 준수(예: GDPR, CCPA) 측면에서도 큰 이점을 제공합니다. 이처럼 RAG는 다양한 산업군에서 AI 기반 서비스의 신뢰성과 효율성을 혁신적으로 높이는 핵심 동력으로 작용하고 있습니다.

RAG 시스템 성공적인 운영을 위한 최적화 전략 및 미래 전망: 지속적인 성능 향상
RAG 시스템 구축은 시작에 불과하며, 성공적인 운영을 위해서는 지속적인 최적화와 관리가 필수적입니다. 첫째, 정기적인 데이터 업데이트가 중요합니다. 사내 문서나 외부 지식 기반이 변경되면 즉시 벡터 데이터베이스에 반영하여 정보의 최신성을 유지해야 합니다. OpenAI의 2024년 9월 업데이트에 따르면, LLM의 'Function Calling' 기능은 외부 데이터베이스와의 연동을 더욱 유연하게 만들어, 실시간 데이터 동기화를 효율적으로 지원합니다. 둘째, 피드백 루프를 구축하여 사용자 피드백을 적극적으로 수집하고 분석해야 합니다. 이를 통해 어떤 질문에서 답변 정확도가 떨어지는지, 어떤 문서가 부족한지 파악하고 시스템을 개선하는 데 활용할 수 있습니다. 예를 들어, 잘못된 답변에 대한 사용자 보고는 검색 증강 전략이나 프롬프트 엔지니어링을 개선하는 중요한 단서가 됩니다.
셋째, 고급 검색 전략 도입으로 RAG 성능을 더욱 향상시킬 수 있습니다. 단순 키워드 매칭을 넘어 사용자 질문의 의도를 파악하는 '의미론적 검색(Semantic Search)', 여러 문서를 종합하여 답변을 구성하는 '멀티-홉 검색(Multi-hop Search)', 그리고 LLM이 검색 쿼리를 스스로 생성하는 '쿼리 확장(Query Expansion)' 등의 기술을 적용할 수 있습니다. 이러한 고급 전략은 RAG 시스템이 더욱 복잡하고 미묘한 질문에도 정확하게 답변하도록 돕습니다. 2026년에는 이와 같은 고급 검색 기술과 LLM의 추론 능력이 결합되어, RAG 시스템의 답변 정확도가 현재보다 최소 1.5배 이상 향상될 것으로 예측됩니다 (IDC FutureScape, 2026).
RAG 시스템의 미래는 더욱 밝습니다. 현재는 주로 텍스트 데이터에 초점을 맞추고 있지만, 향후에는 멀티모달 RAG가 발전하여 이미지, 음성, 비디오 등 다양한 형태의 사내 데이터를 검색하고 활용하는 방향으로 진화할 것입니다. 예를 들어, 제조 현장의 이미지 데이터에서 불량 정보를 추출하거나, 고객센터 녹취록에서 특정 감성을 분석하여 LLM이 답변을 증강하는 시나리오가 가능해질 것입니다. 또한, 소규모 도메인 특화 LLM과 RAG를 결합하여 더욱 빠르고 효율적인 온프레미스(On-premise) 솔루션 구축도 가속화될 것으로 보입니다. 이러한 발전은 기업이 AI를 통해 얻을 수 있는 가치를 극대화하고, 새로운 비즈니스 기회를 창출하는 데 핵심적인 역할을 할 것입니다.
핵심 요약:
RAG 시스템은 LLM의 할루시네이션 및 정보 부족 한계를 해결하며, 사내 문서 기반 답변 정확도를 2배 이상 향상시킵니다.
5단계 구축 가이드(데이터 수집/전처리, 임베딩/벡터 DB, LLM 연동/프롬프트 엔지니어링, RAG 체인/UI 개발, 평가/개선)를 통해 실용적인 시스템 구축이 가능합니다.
LangChain, ChromaDB, OpenAI 임베딩 등 검증된 기술 스택으로 효율적인 RAG 파이프라인을 구성할 수 있습니다.
KB국민카드 등 실제 기업 사례에서 보듯이, RAG는 환각 현상을 50% 이상 감소시키고 업무 생산성 및 고객 만족도를 크게 높입니다.
정기적인 데이터 업데이트, 피드백 루프, 고급 검색 전략 도입은 RAG 시스템의 지속적인 성능 향상과 성공적인 운영을 위한 필수 요소입니다.
자주 묻는 질문
Q. RAG 시스템 구축 시 가장 중요한 요소는 무엇인가요? A. RAG 시스템 구축의 가장 중요한 요소는 고품질의 사내 데이터 수집 및 전처리입니다. 아무리 좋은 LLM과 임베딩 모델을 사용하더라도, 원본 데이터의 품질이 낮으면 정확한 답변을 기대하기 어렵습니다. 데이터 분할(Chunking) 전략과 노이즈 제거 과정이 답변 정확도에 직접적인 영향을 미칩니다.
Q. RAG와 Fine-tuning 중 어떤 방식을 선택해야 할까요? A. 대부분의 사내 데이터 활용 시나리오에서는 RAG가 더 현실적이고 비용 효율적인 해결책입니다. RAG는 LLM을 재학습시키지 않아 비용과 시간을 절약하고, 데이터 업데이트가 용이하며, 답변의 출처를 명확히 제시할 수 있어 투명성이 높습니다. Fine-tuning은 특정 어조나 스타일을 학습시키거나, RAG로도 해결하기 어려운 희귀한 도메인 지식을 LLM에 내재화해야 할 때 고려할 수 있습니다.
Q. RAG 시스템의 성능을 측정하는 지표에는 어떤 것들이 있나요? A. RAG 시스템의 성능은 크게 답변의 정확성(Faithfulness), 관련성(Relevance), 문맥 정확성(Context Precision), 그리고 사용자 만족도로 측정할 수 있습니다. RAGAS와 같은 평가 프레임워크를 사용하면 이러한 지표들을 자동화된 방식으로 평가하고, 시스템 개선을 위한 구체적인 인사이트를 얻을 수 있습니다.
참고자료
- Top Strategic Technology Trends 2024 - Gartner (2024)
- Claude 3 Opus and the State of RAG - Anthropic Research (2024)
- What is a Vector Database? - Pinecone Official Documentation
- The State of AI in 2024 and the next wave of enterprise value - McKinsey (2024)
- Ragas Official Documentation - RAGAS (2024)
이 글이 도움이 되셨다면 공유해 주세요.


