
LLM 에이전트와 코드 인터프리터란 무엇인가요?
LLM 에이전트와 코드 인터프리터는 인공지능이 스스로 판단하고 코드를 실행하여 복잡한 업무를 자동화하는 기술입니다. 이 조합은 특히 데이터 분석, 보고서 작성 등 동적인 문제 해결에서 인간의 개입을 최소화하며 획기적인 효율을 제공합니다. 2026년 4월 현재, Gartner의 전망에 따르면 기업의 35% 이상이 LLM 에이전트 기반 자동화를 시범 운영 중이며, 이는 2024년 대비 2배 이상 증가한 수치입니다.
LLM 에이전트는 단순히 질문에 답하는 것을 넘어, 목표를 설정하고, 계획을 세우며, 외부 도구를 사용하여 그 계획을 실행하는 자율적인 AI 시스템을 의미합니다. 예를 들어, 웹 검색, 데이터베이스 조회, API 호출 등의 작업을 스스로 판단하여 수행합니다. OpenAI와 Anthropic 같은 선두 기업들은 이러한 에이전트의 '추론(reasoning)' 및 '도구 사용(tool-use)' 능력을 지속적으로 고도화하고 있습니다. 이는 사람이 직접 스크립트를 작성하고 실행하는 것보다 훨씬 유연하고 동적인 자동화를 가능하게 합니다.
코드 인터프리터는 LLM 에이전트가 생성한 코드를 안전한 환경에서 직접 실행하고, 그 결과를 다시 에이전트에게 피드백하는 모듈입니다. 이는 LLM이 데이터 처리, 복잡한 계산, 통계 분석 등을 수행할 때 필수적입니다. 특히 Python 같은 스크립트 언어를 활용해 데이터 파일을 조작하거나 시각화하는 데 탁월하며, LLM의 '수학적 추론' 능력을 비약적으로 향상시킵니다. 이 기능 덕분에 LLM은 단순한 텍스트 생성을 넘어 실제 데이터와 상호작용하며 문제를 해결할 수 있게 됩니다.

복합 업무 자동화, 왜 지금 LLM 에이전트가 필요한가요?
기존의 RPA(로봇 프로세스 자동화)나 스크립트 기반 자동화는 규칙이 명확하고 반복적인 업무에 강했지만, 비정형 데이터를 처리하거나 동적으로 변화하는 상황에 대응하기 어려웠습니다. 하지만 LLM 에이전트는 자연어 이해 능력과 추론 기능을 바탕으로 규칙이 모호하고 복잡한 업무까지 자동화할 수 있습니다. 2025년 McKinsey 보고서에 따르면, LLM 에이전트 도입 기업은 평균 30% 이상의 업무 처리 시간 단축 효과를 경험했으며, 이는 곧 비용 절감으로 이어지고 있습니다.
LLM 에이전트 자동화는 크게 세 가지 핵심 이점을 제공합니다. 첫째, 시간 및 비용 절감입니다. 수작업으로 몇 시간이 걸리던 데이터 분석과 보고서 초안 작성을 단 몇 분 만에 완료하여 인건비와 운영 비용을 절감합니다. 둘째, 정확도 및 일관성 향상입니다. 인간의 실수나 편향 없이 일관된 논리와 데이터를 바탕으로 작업을 수행합니다. 셋째, 확장성 및 유연성입니다. 새로운 도구를 쉽게 통합하고 다양한 업무 시나리오에 빠르게 적응할 수 있습니다. 예를 들어, Google의 Vertex AI Agent Builder는 이러한 확장성을 강조하며, 다양한 서드파티 서비스와의 연동을 지원합니다.
실제로 많은 기업들이 LLM 에이전트를 도입하여 혁신적인 성과를 내고 있습니다. 한 금융 기업은 LLM 에이전트와 코드 인터프리터를 활용해 일일 시장 동향 보고서 작성 시간을 8시간에서 1시간으로 87.5% 단축했습니다. 또한, 고객 서비스 부문에서는 챗봇이 처리할 수 없었던 복합적인 고객 문의를 LLM 에이전트가 직접 분석하고 해결책을 찾아내 고객 만족도를 20% 이상 향상시켰다는 MIT Technology Review의 사례도 있습니다. 이처럼 LLM 에이전트는 비즈니스 전반의 효율을 극대화하고 경쟁 우위를 확보하는 핵심 기술로 자리 잡고 있습니다. McKinsey – The economic potential of generative AI (2023)
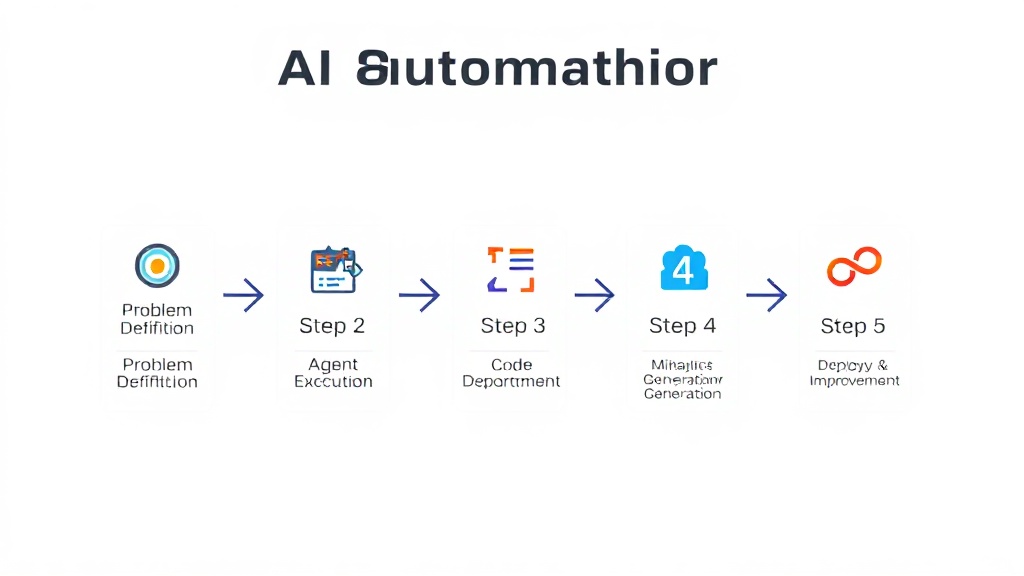
LLM 에이전트 기반 복합 업무 자동화 5단계 실전 가이드
- 단계 1: 문제 정의 및 도구 선정: 먼저 자동화하려는 복합 업무를 명확히 정의하고, 필요한 데이터와 외부 도구를 파악해야 합니다. 예를 들어, '엑셀 파일의 판매 데이터를 분석하여 월별 매출 추이를 파악하고 보고서 초안 작성'과 같은 구체적인 목표를 세우세요. OpenAI의 GPT-4o나 Anthropic의 Claude 3.5 Sonnet과 같이 강력한 추론 능력을 가진 LLM을 선정하고, 관련 API 키를 확보합니다. 이 초기 단계에서 문제의 범위와 기대 성과를 명확히 설정하는 것이 성공적인 자동화의 첫걸음입니다.
- 단계 2: 에이전트 설계 및 프롬프트 엔지니어링: 에이전트에게 명확한 역할과 목표를 부여하는 것이 중요합니다. '데이터 분석가' 역할을 맡기고, 어떤 종류의 정보를 추출하고 싶으며, 어떤 형식으로 결과를 보고 싶은지 상세히 프롬프트로 지시합니다. '단계별 사고(Chain-of-Thought, CoT)' 프롬프트 전략을 활용하여 에이전트가 문제를 풀어나가는 과정을 명확히 지시하세요. 예를 들어, '먼저 파일을 읽고, 데이터 클리닝 후 주요 통계를 계산하고, 시각화 아이디어를 제안하라'와 같이 구체적인 지침을 제공하면 에이전트의 성능이 크게 향상됩니다.
- 단계 3: 코드 인터프리터 활용 데이터 처리 및 분석: 이 단계에서 에이전트는 주어진 데이터를 바탕으로 파이썬 코드를 생성하고, 코드 인터프리터를 통해 실행합니다. 다음은 LLM API를 사용하여 코드 인터프리터 기능을 연동하는 파이썬 코드 예시입니다. 이 코드는 에이전트가 데이터를 분석하고 결과를 반환하는 핵심적인 로직을 담고 있으며, 실제 환경에서는 이 'execute_python_code' 함수가 안전한 샌드박스 환경에서 실행됩니다.
import os import json from openai import OpenAI # OpenAI API 키 설정 (환경 변수 권장) client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY")) def execute_python_code(code: str) -> dict: """Execute Python code in a sandboxed environment and return its output.""" try: # WARNING: For production, this MUST be run in a securely sandboxed environment # (e.g., Docker container, dedicated serverless function) to prevent malicious code execution. # This simple eval/exec is for demonstration only and is highly insecure. exec_globals = {} # Redirect stdout to capture print statements import io import sys old_stdout = sys.stdout redirected_output = io.StringIO() sys.stdout = redirected_output exec(code, exec_globals) output = redirected_output.getvalue() sys.stdout = old_stdout # Restore stdout return {"result": "Code executed successfully.", "output": output, "variables": {k: str(v) for k,v in exec_globals.items() if not k.startswith('__')}} except Exception as e: return {"error": str(e)} def run_data_analysis_agent(user_query: str, data_content: str) -> str: messages = [ {"role": "system", "content": "You are a helpful data analysis assistant. You can write and execute Python code using the 'execute_python_code' tool. Always show your thought process and analyze data step by step. When asked to analyze data, always start by loading the data into a pandas DataFrame. You MUST ensure that any generated code is self-contained and does not rely on external file access beyond the provided data_content. If you need to output results or plots, describe them in text format."}, {"role": "user", "content": f"Analyze the following data and provide insights:\nDATA:\n``\n{data_content}\n``\n\nQuery: {user_query}"} ] tools = [ { "type": "function", "function": { "name": "execute_python_code", "description": "Execute Python code and return its output. Use this for data loading, manipulation, and analysis. The code should be self-contained and avoid external file I/O.", "parameters": { "type": "object", "properties": { "code": { "type": "string", "description": "The Python code to execute." } }, "required": ["code"] } } } ] # First call to LLM response = client.chat.completions.create( model="gpt-4o", # Consider "claude-3-5-sonnet" or other models with tool use capabilities messages=messages, tools=tools, tool_choice="auto", # Let the model decide whether to call a tool or respond directly temperature=0.0 ) response_message = response.choices[0].message tool_calls = response_message.tool_calls if tool_calls: available_functions = {"execute_python_code": execute_python_code} messages.append(response_message) # Extend conversation with assistant's reply # Execute each tool call requested by the model for tool_call in tool_calls: function_name = tool_call.function.name function_to_call = available_functions[function_name] function_args = json.loads(tool_call.function.arguments) function_response = function_to_call(code=function_args.get("code")) messages.append( { "tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": json.dumps(function_response), } ) # Second call to LLM to get a final response based on tool output second_response = client.chat.completions.create( model="gpt-4o", messages=messages ) return second_response.choices[0].message.content else: # If no tool call was made, return the direct response return response_message.content # Example Usage (replace data_sample with actual file content if necessary) # import pandas as pd # data_sample = "Date,Product,Sales\n2024-01-01,A,100\n2024-01-01,B,50\n2024-01-02,A,120\n2024-01-02,C,70" # query = "Calculate total sales per product and identify the best-selling product. Then suggest a simple visualization for monthly trends." # result = run_data_analysis_agent(query, data_sample) # print(result) - 단계 4: 결과 검증 및 보고서 자동 생성: 코드 인터프리터에서 얻은 분석 결과를 바탕으로 에이전트는 최종 보고서 초안을 작성합니다. 이때 '분석 결과 요약', '주요 인사이트 도출', '향후 전략 제안' 등 보고서의 구성 요소를 명확히 지시하는 프롬프트를 사용합니다. 생성된 보고서는 반드시 인간 전문가가 팩트 체크와 최종 검토를 거쳐야 합니다. 에이전트의 출력물은 초안으로서의 가치를 가지며, 최종 의사결정은 여전히 인간의 몫이라는 점을 명심해야 합니다. 이 단계에서 인간의 판단과 AI의 효율성이 결합되어 최상의 결과물을 만들어낼 수 있습니다.
- 단계 5: 배포 및 지속적인 개선: 완성된 에이전트 시스템은 실제 업무 환경에 배포되어 활용됩니다. 예를 들어, 사내 데이터 분석 플랫폼에 통합하거나, 정기 보고서 생성 스케줄러에 연동할 수 있습니다. 에이전트의 성능을 지속적으로 모니터링하고, 새로운 데이터나 업무 요구사항에 맞춰 프롬프트와 도구 연동을 업데이트해야 합니다. 사용자 피드백을 수집하고 에이전트의 동작 방식을 개선하는 반복적인 과정을 통해 자동화의 정확도와 효율성을 더욱 높일 수 있습니다. 관련 내용은 LLM 서비스 프로덕션 최적화 5단계 글에서 더 자세히 다루고 있습니다.
실전 활용 팁 및 LLM 에이전트 도입 시 주의할 점
성공적인 LLM 에이전트 구축을 위해서는 몇 가지 핵심적인 팁을 기억해야 합니다. 첫째, 명확하고 구체적인 프롬프트가 핵심입니다. 에이전트가 수행해야 할 작업, 사용 가능한 도구, 원하는 출력 형식을 최대한 상세히 지시해야 에이전트의 '환각(Hallucination)' 현상을 줄이고 정확도를 높일 수 있습니다. Anthropic의 최신 연구(2025)에 따르면, 컨텍스트 내 예시(in-context learning)를 풍부하게 제공하는 것이 에이전트의 성능을 15% 이상 향상시키는 것으로 나타났습니다. 좋은 프롬프트는 에이전트를 위한 상세한 로드맵과 같습니다.
LLM 에이전트와 코드 인터프리터를 사용할 때는 보안 및 데이터 프라이버시에 각별히 유의해야 합니다. 코드 인터프리터는 외부 코드를 실행하므로 반드시 샌드박스 처리된 환경에서 운영해야 합니다. 민감한 데이터는 익명화하거나 마스킹 처리하여 LLM에 입력해야 하며, KISA(한국인터넷진흥원)의 가이드라인(2024)을 참고하여 데이터 보안 프로토콜을 철저히 준수해야 합니다. 내부망에 구축된 프라이빗 LLM을 활용하는 것도 좋은 대안이 될 수 있습니다. 이는 특히 기업의 기밀 데이터를 다룰 때 중요한 고려 사항이 됩니다. KISA 공식 웹사이트
또한, LLM 에이전트의 비용 효율적인 운영 전략을 수립하는 것이 중요합니다. API 호출 횟수, 토큰 사용량에 따라 비용이 발생하므로, 불필요한 호출을 줄이고 효율적인 프롬프트 디자인을 통해 토큰 사용량을 최적화해야 합니다. 작업의 중요도에 따라 GPT-4o와 같은 고성능 모델과 GPT-3.5 Turbo와 같은 저비용 모델을 적절히 혼용하는 전략도 고려할 수 있습니다. 사람의 최종 검토는 AI 자동화의 한계를 보완하고 신뢰성을 확보하는 데 필수적입니다. 자동화는 생산성을 높이지만, 중요한 의사결정은 여전히 인간의 전문성에 기반해야 함을 잊지 마세요.

자주 묻는 질문
Q. LLM 에이전트 구축에 어떤 기술 스택이 필요한가요? A. 주로 Python 언어와 LangChain, LlamaIndex와 같은 에이전트 프레임워크가 활용됩니다. 여기에 OpenAI, Anthropic 등 LLM 제공사의 API를 연동하고, 데이터 처리 및 분석을 위한 Pandas, NumPy 등의 라이브러리 지식이 필요합니다. 클라우드 환경에서 배포한다면 AWS, Azure, GCP에 대한 이해도 도움이 됩니다.
Q. 코드 인터프리터를 사용하면 보안 문제는 없나요? A. 코드 인터프리터는 임의의 코드를 실행하므로, 보안이 가장 중요합니다. 반드시 외부와 격리된 샌드박스(Sandbox) 환경, 예를 들어 Docker 컨테이너나 자체 격리된 서버에서 코드를 실행해야 합니다. 민감한 시스템 자원에 접근을 제한하고, 실행 시간 및 리소스 사용량을 모니터링하여 잠재적인 위협을 차단해야 합니다.
Q. 소규모 기업도 LLM 에이전트 자동화를 도입할 수 있나요? A. 네, 충분히 가능합니다. 초기에는 복잡한 시스템 구축보다는 특정 반복 업무(예: 데이터 요약, 간단한 보고서 초안 작성)에 ChatGPT Plus의 코드 인터프리터 기능이나 Claude Pro의 도구 사용 기능을 활용하는 것만으로도 큰 효과를 볼 수 있습니다. 점진적으로 자동화 범위를 확장하며 맞춤형 에이전트를 개발하는 전략을 추천합니다.
Q. LLM 에이전트의 환각 현상은 어떻게 관리하나요? A. 환각 현상은 LLM의 고질적인 문제입니다. 이를 관리하기 위해 RAG(검색 증강 생성) 기법을 활용하여 에이전트에게 최신 정보나 내부 데이터를 제공하고, 'CoT(Chain-of-Thought)' 프롬프트로 추론 과정을 명확히 지시합니다. 가장 중요한 것은 인간의 최종 검토와 검증 과정을 반드시 거치는 것입니다. 핵심적인 의사결정은 AI에 전적으로 맡기지 않아야 합니다.
참고자료
- The economic potential of generative AI - McKinsey (2023)
- Gartner Predicts How Generative AI Will Impact Businesses in 2024 - Gartner (2023)
- MIT Technology Review Official Website
- 한국인터넷진흥원 (KISA) 공식 웹사이트
- Function Calling and other API updates - OpenAI (2023)
이 글이 도움이 되셨다면 공유해 주세요.


