
RAG, 왜 지금 필수인가요? LLM의 한계를 넘어서는 전략
LLM(대규모 언어 모델)은 우리 삶과 비즈니스에 혁신을 가져왔지만, 고유한 한계를 가지고 있습니다. 모델 학습 시점 이후의 최신 정보를 반영하지 못하거나, 학습 데이터에 없는 내용을 '지어내는' 환각(Hallucination) 현상으로 인해 잘못된 정보를 제공할 수 있다는 점이 대표적입니다. 2024년 Gartner 보고서에 따르면, 기업의 LLM 도입 시 가장 큰 걸림돌 중 하나로 '정보의 정확성 및 신뢰성 부족'이 꼽혔습니다. 이러한 한계는 비즈니스 의사결정이나 민감한 고객 서비스에 LLM을 활용하는 데 큰 제약이 됩니다.
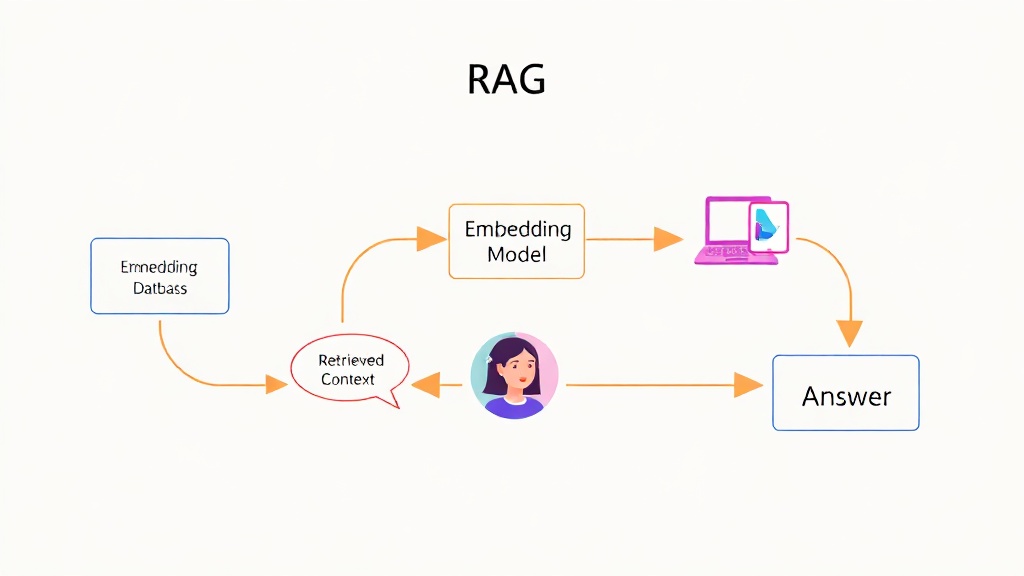
이러한 LLM의 고질적인 문제를 해결하기 위해 등장한 것이 바로 RAG(검색 증강 생성, Retrieval-Augmented Generation) 시스템입니다. RAG는 LLM이 답변을 생성하기 전에 외부의 신뢰할 수 있는 데이터 소스에서 관련 정보를 검색하고 이를 참조하여 답변을 생성하도록 돕는 아키텍처입니다. 이는 마치 학생이 시험을 보기 전에 참고 서적을 찾아보는 것과 같은 원리입니다. Microsoft 연구 결과에 따르면, RAG를 적용했을 때 LLM의 답변 정확도가 평균 2배 이상 향상되었으며, 환각 현상은 50% 이상 감소하는 효과를 보였습니다. 2025년에는 대부분의 기업 LLM 서비스에 RAG가 필수로 탑재될 것으로 전망됩니다.
RAG 시스템의 핵심 구성 요소 중 하나가 바로 벡터 데이터베이스(Vector Database)입니다. 벡터 데이터베이스는 방대한 양의 비정형 데이터를 효율적인 벡터 형태로 저장하고, 사용자 질의와 가장 유사한 정보를 빠르게 찾아내는 역할을 수행합니다. 본 글에서는 RAG 시스템의 작동 원리를 깊이 있게 이해하고, 2026년 4월 현재 가장 주목받는 벡터 데이터베이스 3대장인 Pinecone, Milvus, Qdrant를 심층 비교하며, 여러분의 서비스에 최적화된 RAG 시스템을 구축하는 실전 가이드를 제공하겠습니다.

임베딩과 벡터 데이터베이스: RAG 시스템의 작동 원리는?
RAG 시스템이 어떻게 LLM의 한계를 극복하는지 이해하려면, 먼저 '임베딩(Embedding)'과 '벡터 데이터베이스'의 역할을 정확히 알아야 합니다. RAG의 작동 원리는 크게 세 단계로 나눌 수 있습니다. 첫째, 사용자의 질문(Query)이 들어오면 이를 벡터(Vector) 형태로 변환합니다. 둘째, 이 질문 벡터와 가장 유사한 정보를 벡터 데이터베이스에서 검색합니다. 셋째, 검색된 정보를 LLM에 함께 전달하여 답변을 생성하도록 지시합니다. 이 과정에서 LLM은 단순히 학습된 지식에 의존하는 것이 아니라, 외부에서 실시간으로 가져온 최신 데이터를 기반으로 답변을 '증강'하게 됩니다.
임베딩은 텍스트, 이미지, 오디오 등 비정형 데이터를 머신러닝 모델이 이해할 수 있는 고차원 벡터(숫자 배열) 형태로 변환하는 과정입니다. 이때 유사한 의미를 가진 데이터는 벡터 공간에서 서로 가까운 위치에 배치되는 특성을 가집니다. 예를 들어, OpenAI의 text-embedding-ada-002 모델은 텍스트를 1536차원 벡터로 변환하며, 이 벡터들은 문맥적 유사성을 포함합니다. 이렇게 변환된 벡터들은 LLM이 정보를 이해하고 처리하는 데 필수적인 다리 역할을 합니다. 임베딩 모델에 대한 더 자세한 정보는 OpenAI Embedding 공식 문서에서 확인할 수 있습니다.
벡터 데이터베이스는 이처럼 변환된 수십억 개의 임베딩 벡터를 효율적으로 저장하고 관리하며, 사용자의 질의 벡터와 가장 유사한 벡터를 초고속으로 검색하는 데 특화된 데이터베이스입니다. 일반적인 관계형 데이터베이스와 달리, 벡터 데이터베이스는 유사도 검색(Similarity Search)에 최적화된 인덱스 구조(예: HNSW, IVF_FLAT 등)를 사용합니다. 이를 통해 방대한 양의 문서나 지식 베이스에서 몇 밀리초(ms) 만에 가장 관련성 높은 정보를 찾아낼 수 있으며, 이는 LLM 기반 RAG 시스템의 성능과 응답 속도를 결정하는 핵심 요소입니다.
Pinecone, Milvus, Qdrant: RAG 시스템을 위한 벡터 데이터베이스 3대장 비교
2025년 RAG 시스템 구축을 고려한다면, 시장에서 가장 강력한 성능과 유연성을 제공하는 벡터 데이터베이스 3대장, 즉 Pinecone, Milvus, Qdrant를 눈여겨봐야 합니다. 이 세 가지 솔루션은 각각 다른 강점과 특징을 가지고 있어, 여러분의 프로젝트 요구사항에 따라 최적의 선택이 달라질 수 있습니다. 먼저 각 데이터베이스의 주요 특징과 장단점을 살펴보겠습니다.
Pinecone은 완전 관리형(Fully Managed) 벡터 데이터베이스 서비스로, 사용자가 직접 인프라를 구축하거나 관리할 필요 없이 높은 확장성과 성능을 제공합니다. 스타트업부터 대기업까지 다양한 규모의 조직에서 빠르게 프로덕션 환경에 RAG 시스템을 배포하려는 경우에 매우 적합합니다. (출처: Pinecone 공식 웹사이트) 반면, Milvus는 클라우드 네이티브 환경에 최적화된 오픈소스 벡터 데이터베이스로, 자체 호스팅(Self-hosting)이 가능하여 높은 수준의 커스터마이징과 데이터 주권을 확보하려는 기업에 유리합니다. (출처: Milvus 공식 웹사이트) Milvus는 뛰어난 확장성과 다양한 인덱스 지원으로 대규모 데이터셋 처리에도 강점을 보입니다.
마지막으로 Qdrant는 Rust 기반의 오픈소스 벡터 서치 엔진으로, 고성능과 메모리 효율성이 뛰어납니다. 특히, 필터링 기능이 강력하여 벡터 검색 시 특정 메타데이터 조건을 함께 적용해야 하는 복잡한 RAG 시나리오에 매우 유용합니다. Qdrant는 또한 자체 호스팅뿐만 아니라 클라우드 관리형 서비스도 제공하여, 사용자의 편의성을 높였습니다. 2024년 기준, Qdrant는 빠른 개발 속도와 활발한 커뮤니티 지원으로 빠르게 사용자 기반을 확장하고 있습니다. 다음 표에서 이 세 가지 벡터 데이터베이스의 주요 특징을 한눈에 비교해 보세요.
| 특징 | Pinecone | Milvus | Qdrant |
|---|---|---|---|
| 유형 | 완전 관리형 (SaaS) | 오픈소스 (클라우드 네이티브) | 오픈소스 (Rust 기반, 관리형 옵션) |
| 호스팅 | 클라우드 (AWS, GCP, Azure) | 자체 호스팅, 클라우드 | 자체 호스팅, 클라우드 |
| 개발 언어 | - (API 기반) | Go, Python, Java, Node.js | Rust (Python, Go, Node.js 클라이언트) |
| 주요 강점 | 쉬운 사용성, 고성능, 확장성, 빠른 배포 | 대규모 데이터, 유연한 배포, 커스터마이징 | 빠른 검색 속도, 강력한 필터링, 메모리 효율 |
| 적합한 용도 | 빠른 프로토타이핑/배포, 관리 부담 최소화 | 대규모/복잡한 워크로드, 자체 인프라 선호 | 정확한 필터링 필요, 고성능/저지연 요구사항 |
| 비용 모델 | 사용량 기반 (유료) | 오픈소스 (자체 운영), 클라우드 관리형 (유료) | 오픈소스 (자체 운영), 클라우드 관리형 (유료) |
RAG 시스템 구축: 서비스 규모와 목표에 따른 벡터 DB 선택 가이드 및 LangChain 연동 실전 코드
어떤 벡터 데이터베이스를 선택할지는 여러분의 RAG 시스템이 지향하는 목표와 가용 리소스에 따라 달라집니다. 단순히 데이터베이스의 성능만을 고려하기보다는, 초기 구축 비용, 장기적인 운영 및 유지보수 비용, 개발팀의 숙련도, 데이터 보안 및 주권 요구사항 등을 종합적으로 판단해야 합니다. 예를 들어, 스타트업에서 빠르게 PoC(개념 증명)를 진행하고 최소한의 관리 부담으로 프로덕션에 배포하고 싶다면 Pinecone과 같은 완전 관리형 서비스가 유리할 것입니다. 반면, 대규모 엔터프라이즈 환경에서 데이터 주권을 확보하고 세밀한 커스터마이징이 필요하며, 전담 운영팀이 있다면 Milvus나 Qdrant의 자체 호스팅 옵션을 고려할 수 있습니다. 2025년 기준, 많은 기업들이 클라우드 관리형 서비스를 선호하는 추세입니다.
또한, LLM 기반 애플리케이션 개발 프레임워크인 LangChain과의 연동 용이성도 중요한 고려사항입니다. LangChain은 RAG 시스템 구축을 위한 다양한 모듈과 인터페이스를 제공하여 개발 시간을 크게 단축시켜 줍니다. Pinecone, Milvus, Qdrant 모두 LangChain에서 공식적으로 지원하는 벡터스토어(Vectorstore)이므로, 개발 편의성 측면에서는 큰 차이가 없습니다. 중요한 것은 각 벡터 데이터베이스의 API 호출 방식과 쿼리 최적화 옵션을 이해하고 활용하는 것입니다. 더 심층적인 LLM 파인튜닝 가이드에 관심이 있다면 2025년 LLM 비용 효율적 파인튜닝 실전 가이드 글을 참고해 보세요.
이제 LangChain과 Qdrant를 활용하여 간단한 RAG 시스템을 구축하는 코드 예시를 살펴보겠습니다. 이 예시는 문서에서 관련 정보를 검색하고 LLM에 전달하는 기본적인 RAG 워크플로우를 보여줍니다. 실제 프로덕션 환경에서는 더 복잡한 데이터 전처리 및 임베딩 전략이 필요하지만, 기본적인 개념 이해와 실전 감각을 익히는 데 도움이 될 것입니다. 아래 코드는 2026년 4월 Qdrant Python 클라이언트와 LangChain 버전을 기준으로 작성되었습니다.
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Qdrant
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# 1. 환경 변수 설정 (실제 키로 대체)
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Qdrant 클러스터 URL과 API 키를 설정 (Qdrant Cloud 사용 시)
# os.environ["QDRANT_HOST"] = "YOUR_QDRANT_HOST"
# os.environ["QDRANT_API_KEY"] = "YOUR_QDRANT_API_KEY"
# 2. 문서 로드 및 분할
# 실제 파일 경로와 내용을 사용하세요.
loader = TextLoader("example_document.txt", encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents)
# 3. 임베딩 모델 초기화
embeddings = OpenAIEmbeddings()
# 4. Qdrant 벡터 데이터베이스에 문서 임베딩 및 저장
# 로컬 Qdrant 인스턴스 사용 (또는 Qdrant Cloud 연결)
# collection_name은 고유하게 설정
qdrant = Qdrant.from_documents(
split_docs,
embeddings,
location=":memory:", # 로컬 메모리에서 실행 (실제는 URL 지정)
collection_name="my_rag_collection",
force_recreate=True # 테스트용: 컬렉션 재생성
)
# 5. LLM 초기화
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 6. RetrievalQA 체인 생성 (RAG 시스템)
qa_chain = RetrievalQA.from_chain_type(
llm,
chain_type="stuff", # 검색된 모든 문서를 LLM에 한 번에 전달
retriever=qdrant.as_retriever(),
return_source_documents=True
)
# 7. 질문 실행
query = "RAG 시스템의 주요 이점은 무엇인가요?"
result = qa_chain({"query": query})
print("\\n[사용자 질문]")
print(query)
print("\\n[LLM 답변]")
print(result["result"])
print("\\n[참조된 문서 (소스)]")
for doc in result["source_documents"]:
print(f"- {doc.metadata['source']} ({doc.metadata.get('page', 'N/A')}): {doc.page_content[:100]}...")
핵심 요약
- LLM의 한계 극복: RAG는 LLM의 환각 현상과 최신 정보 부족 문제를 해결하는 필수 아키텍처입니다.
- 핵심 구성 요소: 임베딩 모델은 텍스트를 벡터로 변환하고, 벡터 데이터베이스는 이 벡터들을 효율적으로 저장 및 유사도 검색을 수행합니다.
- 주요 벡터 DB: Pinecone (관리형), Milvus (오픈소스, 확장성), Qdrant (오픈소스, 필터링)는 RAG 시스템 구축을 위한 강력한 선택지입니다.
- 선택 기준: 프로젝트의 규모, 예산, 관리 용이성, 개발 역량, 데이터 주권 요구사항 등을 종합적으로 고려하여 최적의 벡터 DB를 선택해야 합니다.
- 실전 구축: LangChain과 같은 프레임워크를 활용하면 효율적으로 RAG 시스템을 개발하고 벡터 데이터베이스와 연동할 수 있습니다.
자주 묻는 질문
Q. RAG 시스템을 구축하는 데 벡터 데이터베이스가 반드시 필요한가요? A. 네, RAG 시스템의 핵심은 외부 지식 소스에서 관련 정보를 효율적으로 검색하는 것입니다. 벡터 데이터베이스는 이러한 수십억 개의 비정형 데이터를 벡터 형태로 저장하고 초고속으로 유사도 검색을 수행하는 데 특화되어 있어, RAG 시스템 구축 시 필수적인 요소로 간주됩니다. 기존 관계형 데이터베이스로는 이러한 고차원 벡터 유사도 검색을 효율적으로 처리하기 어렵습니다.
Q. Pinecone, Milvus, Qdrant 외에 다른 벡터 데이터베이스도 있나요? A. 물론입니다. ElasticSearch의 벡터 검색 기능, Weaviate, Chroma, PGvector(PostgreSQL 확장) 등 다양한 벡터 데이터베이스 및 벡터 검색 솔루션이 존재합니다. 이 글에서는 2025년 기준 가장 대중적이고 활용도가 높은 3대장을 비교했지만, 각 솔루션마다 특정 기능이나 배포 방식에 강점이 있으므로, 여러분의 특정 요구사항에 맞춰 더 폭넓게 조사해 볼 것을 권장합니다.
Q. RAG 시스템 구축 시 LLM과 임베딩 모델은 어떤 것을 사용하는 것이 좋은가요?
A. LLM은 사용 목적과 성능 요구사항에 따라 OpenAI의 GPT-4, Anthropic의 Claude 3, Google의 Gemini 등 다양한 모델을 선택할 수 있습니다. 임베딩 모델 역시 OpenAI의 text-embedding-ada-002, Google의 PaLM 임베딩, 또는 허깅페이스(Hugging Face)의 오픈소스 모델(예: BAAI/bge-large-en-v1.5) 등 다양한 선택지가 있습니다. 데이터의 종류와 언어, 그리고 비용 효율성을 고려하여 최적의 모델 조합을 선택하는 것이 중요합니다.
참고자료
- Gartner Predicts by 2025, Generative AI Will Be a Top 5 Priority for 70 Percent of CEOs - Gartner (2024)
- Retrieval Augmented Generation (RAG) is a Key Component for Next Generation AI Systems - Microsoft Research (2023)
- Pinecone Official Website
- Milvus Official Website
- Qdrant Official Website
- OpenAI Embeddings - Official Documentation
이 글이 도움이 되셨다면 공유해 주세요.


