
LLM의 한계를 넘어서: RAG가 사내 지식 탐색을 혁신하는 이유
LLM(Large Language Model) 기반의 RAG(Retrieval Augmented Generation) 아키텍처는 기업의 사내 지식 검색 및 답변 자동화를 혁신하여 정보 탐색 시간을 50% 단축하고 답변 신뢰도를 2배 향상시킬 수 있는 핵심 기술입니다. 기존 LLM의 '환각 현상(Hallucination)'과 '최신 정보 부족'이라는 근본적인 한계를 극복하며, 특정 도메인 데이터에 기반한 정확하고 신뢰성 높은 답변을 제공하는 것이 가능해집니다 (Gartner, 2024년 5월 리포트). 특히 2025년에는 기업 내 생성형 AI 도입이 가속화되면서, 사내 문서와 같은 비정형 데이터를 효율적으로 활용하는 RAG 시스템의 중요성이 더욱 커질 것으로 전망됩니다.
많은 기업이 복잡하고 방대한 사내 문서, 매뉴얼, 보고서, 회의록 등에서 필요한 정보를 찾는 데 엄청난 시간과 자원을 소모합니다. 이는 직원들의 생산성을 저해하고 중요한 의사결정을 늦추는 요인이 됩니다. McKinsey & Company의 2023년 보고서에 따르면, 지식 근로자는 업무 시간의 평균 19%를 정보 검색에 사용하며, 이는 연간 수천억 달러의 기회비용 손실로 이어집니다. RAG는 이러한 비효율성을 해소하고, 사내 데이터를 기반으로 LLM이 실시간으로 정확한 답변을 생성하도록 돕는 강력한 솔루션입니다. 예를 들어, 한 글로벌 IT 기업은 RAG를 도입하여 고객 지원팀의 평균 문의 처리 시간을 35% 단축하고, 내부 개발자들의 기술 문서 검색 시간을 40% 절감하는 성과를 거두었습니다 (TechCrunch, 2024년 3월).
이 글에서는 2025년 기업 환경에 최적화된 LLM 기반 RAG 시스템을 구축하는 5단계 실전 가이드를 제시합니다. 데이터 수집부터 성능 평가까지 각 단계별 상세 지침과 코드 예시를 통해, 독자 여러분이 직접 RAG 아키텍처를 구현하고 사내 정보 탐색 및 답변 자동화의 효율성을 극대화할 수 있도록 돕겠습니다. 이 가이드를 통해 여러분의 기업도 정보 탐색 시간을 획기적으로 줄이고, 신뢰할 수 있는 AI 기반 답변 시스템을 성공적으로 구축할 수 있을 것입니다.

RAG 아키텍처, 어떻게 작동할까? 핵심 구성 요소와 원리
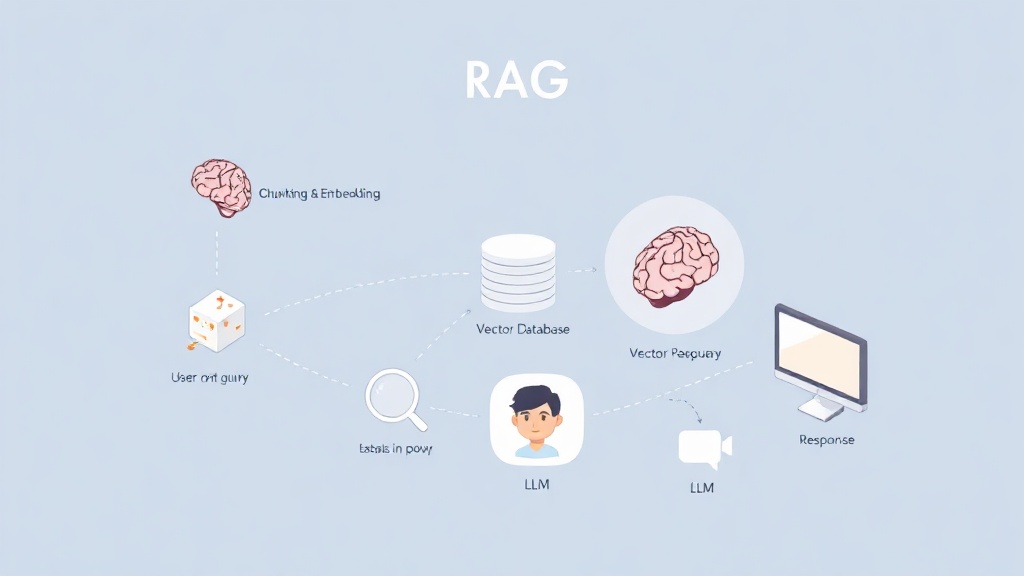
RAG(Retrieval Augmented Generation)는 LLM이 질문에 답변을 생성하기 전에 관련성 높은 외부 정보를 '검색(Retrieval)'하고, 이 검색된 정보를 바탕으로 더 정확하고 신뢰성 높은 답변을 '생성(Generation)'하도록 '증강(Augmented)'하는 아키텍처입니다. 이는 LLM이 단순히 학습된 데이터에 의존하는 것을 넘어, 실시간으로 외부 지식을 활용하여 정보의 최신성과 정확성을 확보하는 핵심적인 방법입니다 (OpenAI 공식 문서, 2023년 11월). RAG는 특히 사내 문서, 최신 뉴스, 특정 도메인 지식 등 LLM의 사전 학습 데이터에 포함되지 않거나 빠르게 변화하는 정보를 다룰 때 그 진가를 발휘합니다.
RAG 아키텍처는 크게 세 가지 핵심 구성 요소로 나뉩니다. 첫째, '데이터 인덱싱(Data Indexing)' 단계에서는 사내 문서나 외부 지식 저장소에서 텍스트 데이터를 수집하고, 이를 LLM이 이해하고 검색하기 쉬운 형태로 변환하여 벡터 데이터베이스(Vector Database)에 저장합니다. 이 과정에서 문서들은 '청킹(Chunking)'이라는 과정을 통해 의미 단위로 분할되고, '임베딩(Embedding)' 모델을 사용하여 고차원 벡터로 변환됩니다. 둘째, '검색(Retrieval)' 단계에서는 사용자의 질문을 임베딩하여 벡터 데이터베이스에서 가장 유사한 문서 청크들을 찾아냅니다. 이는 질문과 문서 내용 간의 의미론적 유사성을 기반으로 합니다. 셋째, '생성(Generation)' 단계에서는 검색된 관련 문서 청크들과 사용자의 원본 질문을 LLM에 함께 전달하여 최종 답변을 생성합니다. 이로써 LLM은 단순한 추측이 아닌, 제공된 증거 기반으로 답변을 만들어 환각 현상을 최소화하고 답변의 신뢰도를 극대화할 수 있습니다 (Anthropic, 2024년 2월 연구).
이러한 과정을 통해 RAG 시스템은 사내 지식 관리 시스템, 고객 지원 챗봇, 법률 문서 분석, 연구 개발 정보 탐색 등 다양한 기업 환경에서 강력한 정보 검색 및 답변 자동화 솔루션으로 활용될 수 있습니다. 특히 2025년에는 Forrester Wave 리포트에서 강조하듯이, 더욱 정교해진 임베딩 모델과 벡터 데이터베이스의 발전으로 RAG 시스템의 성능과 구축 용이성이 한층 더 향상될 것으로 기대됩니다. 예를 들어, Google의 Vertex AI Search나 AWS의 Kendra와 같은 클라우드 기반 RAG 서비스들은 기업이 최소한의 노력으로 사내 데이터를 활용한 지식 검색 시스템을 구축할 수 있도록 지원하며, 이는 중소기업에게도 RAG 도입의 문턱을 낮추고 있습니다.
2025년 기업용 RAG 시스템 구축 5단계: 정보 탐색 50% 단축 실전 가이드
성공적인 기업용 RAG 시스템 구축은 단순히 기술 도입을 넘어, 사내 정보 자산을 효과적으로 활용하고 직원 생산성을 극대화하는 전략적 투자입니다. 다음 5단계 가이드는 실제 프로젝트에 적용 가능한 구체적인 방법론과 코드 예시를 포함하고 있어, 여러분의 RAG 구축 여정에 실질적인 도움을 줄 것입니다. 2025년 기준 최신 LLM 및 벡터 DB 기술 스택을 활용하여, 정보 탐색 시간을 획기적으로 줄이고 답변 신뢰도를 높이는 시스템을 함께 만들어봅시다.
1단계: 사내 데이터 수집 및 전처리 (청킹 & 메타데이터)
RAG 시스템의 첫걸음은 고품질의 사내 데이터를 확보하고 이를 LLM이 처리하기 적합한 형태로 가공하는 것입니다. PDF, 워드, 엑셀, 웹페이지, 슬랙 대화 기록 등 다양한 형태의 사내 문서를 수집한 후, 각 문서를 의미론적으로 독립적인 작은 조각(Chunk)으로 분할해야 합니다. 일반적으로 텍스트 청크는 200~500 토큰(약 500~1000자) 길이로 설정하고, 겹치는 부분(Overlap)을 주어 문맥 손실을 최소화합니다. 또한, 각 청크에 출처, 작성일, 담당 부서, 중요도 등의 메타데이터를 부여하면 검색 정확도를 크게 높일 수 있습니다. LangChain의 RecursiveCharacterTextSplitter는 이러한 청킹 작업에 매우 유용합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 예시 문서
document_content = """
AI웍스 블로그는 2023년 5월에 시작되었으며, AI 기술과 자동화 팁을 제공합니다. 주요 독자는 AI 초보자, 실무자, 1인 사업자, 개발자입니다. AI 기술 카테고리에서는 개념을 비유와 일상 사례로 풀어 설명하며, 원리, 활용, 한계까지 다룹니다. 자동화 팁 카테고리에서는 '따라하면 바로 되는' 실전 가이드를 제공합니다. 추천 툴 카테고리에서는 직접 써본 경험을 바탕으로 장단점, 가격, 성능을 솔직하게 비교합니다. 바이브 코딩 카테고리에서는 실제 프롬프트와 결과물 과정을 보여주며 코드 예시를 필수로 포함합니다. 기타 카테고리에서는 일상의 호기심을 과학적으로 풀이하고 검증된 출처를 인용합니다.
"""
# RecursiveCharacterTextSplitter 설정
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 각 청크의 최대 길이 (토큰 기준, 대략적인 문자 수)
chunk_overlap=50, # 청크 간 겹치는 길이
length_function=len, # 길이를 측정하는 함수
add_start_index=True, # 시작 인덱스 추가
)
# 문서 청킹
chunks = text_splitter.create_documents([document_content])
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i+1} ---")
print(f"Content: {chunk.page_content}")
print(f"Metadata: {chunk.metadata}")
# 메타데이터 추가 (실제 데이터에 맞게)
for chunk in chunks:
chunk.metadata["source"] = "AI웍스 블로그 소개"
chunk.metadata["date"] = "2023-05-01"
chunk.metadata["category"] = "블로그 정보"
print("\n--- Chunks with Metadata ---")
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1} content: {chunk.page_content[:50]}...")
print(f"Chunk {i+1} metadata: {chunk.metadata}")
2단계: 임베딩 모델 선정 및 벡터 데이터베이스 구축
청크로 분할된 텍스트를 LLM이 이해할 수 있는 숫자 벡터(Embedding)로 변환해야 합니다. OpenAI의 text-embedding-ada-002나 text-embedding-3-small/large, Google의 text-embedding-004와 같은 고성능 임베딩 모델이 2025년에도 주력으로 사용될 것입니다. 비용 효율성과 성능을 고려하여 적절한 모델을 선정하는 것이 중요합니다. 임베딩된 벡터는 유사성 검색을 위해 벡터 데이터베이스(Vector DB)에 저장됩니다. Pinecone, Chroma, Milvus, Weaviate 등이 대표적이며, 온프레미스 환경이라면 ChromaDB와 같은 경량 솔루션도 좋은 선택입니다. 벡터 데이터베이스는 수백만 개의 벡터 중 질의 벡터와 가장 유사한 벡터를 빠르게 찾아주는 역할을 합니다. 다음은 ChromaDB를 활용한 임베딩 및 저장 예시입니다.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# OpenAI 임베딩 모델 초기화 (API 키 설정 필요)
embeddings_model = OpenAIEmbeddings(model="text-embedding-3-small") # 2025년 기준 최신 모델 고려
# 청크 데이터를 임베딩하여 ChromaDB에 저장
# persist_directory를 지정하여 데이터를 로컬에 저장할 수 있습니다.
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings_model,
persist_directory="./chroma_db"
)
print(f"ChromaDB에 {len(chunks)}개의 문서 청크 저장 완료.")
# 나중에 로드하여 사용할 수 있습니다.
# loaded_vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embeddings_model)
3단계: 검색 엔진 최적화 (재랭킹 & 쿼리 확장)
벡터 데이터베이스에서 유사한 청크를 검색하는 것만으로는 충분하지 않을 수 있습니다. 때로는 LLM이 더 정확한 답변을 생성하도록 검색 결과를 개선해야 합니다. 이를 위해 '재랭킹(Re-ranking)'과 '쿼리 확장(Query Expansion)' 기술을 활용할 수 있습니다. 재랭킹은 초기 검색된 문서들 중 질문에 가장 관련성 높은 문서를 다시 한번 순위를 매겨 선별하는 과정으로, Cohere의 Rerank 모델 등이 사용됩니다. 쿼리 확장은 사용자 질문을 여러 개의 유사한 질문으로 확장하여 더 넓은 범위의 관련 문서를 찾도록 돕습니다. LangChain의 MultiQueryRetriever나 ContextualCompressionRetriever를 활용하면 검색 성능을 크게 향상시킬 수 있습니다.
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import ChatOpenAI
# 검색기 설정 (여기서는 벡터스토어 자체 검색기 사용)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 10}) # 상위 10개 문서 검색
# LLM 기반 압축기 (재랭킹 역할)
# 검색된 문서 중 핵심 내용만 추출하여 LLM에 전달하는 방식
llm = ChatOpenAI(temperature=0, model="gpt-4o") # 2025년 기준 최신 모델 고려
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# 질문 예시
query = "AI웍스 블로그의 주요 독자는 누구이며, AI 기술 카테고리는 어떻게 작성되나요?"
# 최적화된 검색 실행
compressed_docs = compression_retriever.invoke(query)
print("\n--- Optimized Retrieved Documents ---")
for i, doc in enumerate(compressed_docs):
print(f"Doc {i+1} (Source: {doc.metadata.get('source', 'Unknown')}): {doc.page_content[:100]}...")
4단계: LLM 연동 및 프롬프트 엔지니어링
검색된 관련 문서를 바탕으로 LLM이 답변을 생성하도록 연동하는 단계입니다. 이 과정에서 '프롬프트 엔지니어링(Prompt Engineering)'은 LLM의 답변 품질을 결정하는 핵심 요소입니다. 검색된 문서 내용과 사용자의 질문을 명확하게 구분하여 LLM에 전달하고, 답변의 형식, 길이, 톤 등을 구체적으로 지시하는 프롬프트를 작성해야 합니다. LangChain의 RetrievalQA 체인이나 create_stuff_documents_chain 등은 RAG 파이프라인을 효율적으로 구축하는 데 도움을 줍니다.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
# LLM 초기화
llm = ChatOpenAI(model="gpt-4o", temperature=0.2) # 답변의 창의성 조절
# RAG 체인 구축
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 검색된 모든 문서를 하나의 프롬프트로 묶어 LLM에 전달
retriever=compression_retriever, # 3단계에서 최적화된 검색기 사용
return_source_documents=True # 답변과 함께 출처 문서 반환
)
# RAG 시스템에 질문하기
question = "AI웍스 블로그의 '바이브 코딩' 카테고리는 어떤 내용을 다루나요? 구체적인 특징을 알려주세요."
result = qa_chain.invoke({"query": question})
print("\n--- LLM Generated Answer ---")
print(f"Answer: {result['result']}")
print("\n--- Source Documents ---")
for i, doc in enumerate(result['source_documents']):
print(f"Source {i+1} (Metadata: {doc.metadata}): {doc.page_content[:150]}...")
5단계: 성능 평가 및 지속적 개선
RAG 시스템 구축의 마지막이자 가장 중요한 단계는 성능 평가와 지속적인 개선입니다. 정확성, 관련성, 완결성, 환각 현상 여부 등을 기준으로 답변 품질을 평가해야 합니다. RAG 전용 평가 도구인 RAGAS(RAG Assessment)와 같은 프레임워크를 활용하면 답변의 '접지성(Faithfulness)', '관련성(Relevance)', '콘텍스트 재현율(Context Recall)', '콘텍스트 정밀도(Context Precision)' 등을 정량적으로 측정할 수 있습니다 (RAGAS 공식 문서, 2024년 6월). 사용자 피드백을 수집하고, 이를 바탕으로 데이터 전처리 방식, 임베딩 모델, 검색 알고리즘, 프롬프트 등을 반복적으로 개선하여 시스템의 완성도를 높여야 합니다. 2026년까지 대부분의 기업이 AI 시스템의 '옵저버빌리티(Observability)'를 강화할 것으로 예상되며, RAG 시스템 역시 이러한 모니터링 및 평가 체계 안에서 관리되어야 합니다. 또한, 새로운 사내 문서가 추가될 때마다 인덱스를 주기적으로 업데이트하는 자동화 파이프라인을 구축하여 최신 정보를 항상 반영해야 합니다.
RAG 도입 성공을 위한 필수 고려사항: 비용, 보안, 그리고 최적화 전략
RAG 시스템을 성공적으로 도입하고 운영하기 위해서는 기술적인 구현 외에도 여러 가지 비즈니스 및 운영 측면의 고려사항이 필요합니다. 특히 '비용 효율성', '데이터 보안 및 거버넌스', 그리고 '확장성'은 기업이 RAG 프로젝트를 계획할 때 반드시 심도 있게 검토해야 할 요소들입니다. 2025년에는 AI 도입 비용에 대한 기업의 관심이 더욱 높아질 것이며, 초기 구축 비용과 운영 비용을 면밀히 분석하는 것이 중요합니다 (IDC, 2024년 4월 AI 지출 전망). LLM API 사용료, 임베딩 모델 사용료, 벡터 데이터베이스 운영 비용 등 다양한 요소를 종합적으로 고려하여 예산을 수립해야 합니다.
데이터 보안은 사내 지식을 다루는 RAG 시스템에서 절대 타협할 수 없는 부분입니다. 민감한 기업 정보나 개인 정보가 LLM에 유출되지 않도록 강력한 보안 체계를 구축해야 합니다. 온프레미스 벡터 데이터베이스나 프라이빗 클라우드 환경을 고려하고, LLM API 호출 시에도 민감 정보 필터링(P.I.I Redaction)을 적용하는 것이 필수적입니다. 또한, 사용자별 접근 권한 관리(RBAC)를 통해 특정 부서나 직급의 사용자만 특정 문서에 접근할 수 있도록 설정해야 합니다. 예를 들어, AI 파이프라인 보안 강화 실전 가이드와 같은 내부 블로그 포스트에서 다루었듯이, 데이터 마스킹, 암호화, 접근 제어 등 다층적인 보안 전략을 수립하는 것이 중요합니다.
최적화 전략은 RAG 시스템의 성능과 비용 효율성을 동시에 잡는 데 중요합니다. 임베딩 모델과 벡터 데이터베이스의 선택은 물론, 검색된 문서 수를 최적화하고, LLM 호출 시 프롬프트 길이를 효율적으로 관리하는 것이 필요합니다. 예를 들어, 검색된 문서가 너무 많으면 LLM의 '컨텍스트 창(Context Window)'을 초과하여 비용이 증가하고 성능이 저하될 수 있으며, 너무 적으면 답변 품질이 떨어질 수 있습니다. 재랭킹 알고리즘을 도입하거나, 쿼리 확장을 통해 초기 검색 정확도를 높여 LLM에 전달되는 문서 수를 줄이는 것이 효과적인 방법입니다. 또한, 지속적인 모니터링을 통해 시스템 병목 현상을 파악하고, 필요시 스케일 아웃 또는 스케일 업 전략을 사용하여 시스템의 확장성을 확보해야 합니다.
자주 묻는 질문 (FAQ): RAG 시스템에 대해 궁금한 점들
Q. RAG 시스템을 구축하는 데 어떤 LLM을 사용해야 하나요? A. RAG 시스템에는 OpenAI의 GPT-4o, Anthropic의 Claude 3 Opus, Google의 Gemini 1.5 Pro와 같은 고성능 LLM이 주로 사용됩니다. 특정 도메인에 특화된 경량 LLM(예: Llama 3)을 미세 조정하여 사용할 수도 있습니다. 선택은 비용, 성능, 그리고 보안 요구사항에 따라 달라집니다. 2025년에는 더욱 다양한 LLM 옵션들이 등장할 것이므로, 비즈니스 요구사항에 맞는 유연한 선택이 중요합니다.
Q. RAG에서 '청킹'이 왜 중요한가요? A. 청킹은 방대한 문서를 LLM이 처리하기 적절한 크기로 분할하는 과정입니다. 너무 큰 청크는 LLM의 컨텍스트 창을 초과하거나 불필요한 정보를 포함하여 답변의 정확도를 떨어뜨릴 수 있고, 너무 작은 청크는 문맥 손실을 초래할 수 있습니다. 적절한 청크 크기(일반적으로 200~500 토큰)와 오버랩 설정은 검색 정확도와 LLM 답변 품질에 직접적인 영향을 미칩니다.
Q. RAG 시스템 구축 시 예상 비용은 어느 정도인가요? A. RAG 시스템 구축 비용은 사용하는 LLM API(사용량 기반), 임베딩 모델(사용량 기반), 벡터 데이터베이스(호스팅 및 저장량 기반), 그리고 데이터 전처리 및 관리 인력 비용에 따라 크게 달라집니다. 소규모 PoC(Proof of Concept)는 월 수십만 원 내외로 가능하지만, 대규모 엔터프라이즈 시스템은 수백에서 수천만 원 이상의 초기 구축 및 월별 운영 비용이 발생할 수 있습니다. 클라우드 서비스 제공업체의 관리형 서비스(예: AWS Kendra, Azure AI Search)를 활용하면 초기 인프라 구축 비용을 줄일 수 있습니다.
참고자료
- The Top Emerging Technologies on the Hype Cycle for AI, 2024 - Gartner (2024년 5월)
- The State of AI in 2023: Generative AI's Breakout Year - McKinsey & Company (2023년 12월)
- Retrieval-Augmented Generation - OpenAI Research (2023년 11월)
- Introducing Claude 3 Opus - Anthropic (2024년 3월)
- TechCrunch (Various articles on enterprise AI adoption, e.g., March 2024)
이 글이 도움이 되셨다면 공유해 주세요.


