
클라우드 ML 학습 비용 50% 절감: SageMaker Spot Training과 분산 학습의 힘
AWS SageMaker Spot Training과 분산 학습은 2025년 클라우드 ML 학습 비용을 50%까지 절감하고, 대규모 모델 학습 시간을 30% 단축하며 리소스 효율을 2배 향상시키는 핵심 전략입니다. 이는 클라우드 제공업체의 유휴 컴퓨팅 자원을 활용하고, 여러 장치에 작업을 분할하여 처리하기 때문입니다. 특히 AI 모델의 복잡성이 증가하고 학습 데이터 규모가 폭발적으로 늘어나면서, 클라우드 ML 학습 비용은 기업의 주요 고민거리 중 하나로 부상하고 있습니다. Gartner의 2024년 보고서에 따르면, AI 인프라 비용은 전체 AI 프로젝트 예산의 평균 40%를 차지하며, 이 중 학습 비용이 상당 부분을 점유하고 있습니다.
많은 기업과 개발자들이 고성능 GPU 인스턴스를 활용하여 대규모 언어 모델(LLM)이나 복잡한 이미지 분류 모델을 학습시키고 있지만, 온디맨드 인스턴스 비용은 빠르게 누적되어 예산을 초과하는 경우가 흔합니다. 이러한 배경 속에서 AWS SageMaker는 개발자들이 효율적으로 ML 모델을 학습시킬 수 있도록 다양한 기능을 제공하며, 그중에서도 Spot Training과 분산 학습은 비용 절감과 성능 향상이라는 두 마리 토끼를 잡을 수 있는 강력한 솔루션으로 주목받고 있습니다.
본 가이드에서는 2025년 기준으로 최신 AWS SageMaker 환경에서 Spot Training을 설정하여 학습 비용을 극적으로 줄이고, 분산 학습 기법을 적용하여 대규모 모델 학습 시간을 단축하는 구체적인 방법을 다룹니다. 또한, 이 두 가지 기술을 효과적으로 결합하여 리소스 효율을 극대화하고, 실제 개발 과정에서 발생할 수 있는 문제점과 그 해결책까지 상세하게 제시하여 여러분의 ML 개발 여정에 실질적인 도움을 드릴 것입니다. McKinsey 2023년 리포트에 따르면, 최적화된 클라우드 리소스 관리를 통해 기업은 평균 20~30%의 클라우드 비용을 절감할 수 있으며, 이는 AI 워크로드에서도 동일하게 적용됩니다.

AWS SageMaker Spot Training: 최대 90% 비용 절감 비법
AWS SageMaker Spot Training은 AWS EC2 Spot 인스턴스를 활용하여 머신러닝 모델을 학습시키는 기능으로, 온디맨드 인스턴스 대비 최대 90%까지 저렴한 가격으로 학습 인스턴스를 사용할 수 있게 해줍니다. Spot 인스턴스는 AWS의 유휴 컴퓨팅 용량을 활용하기 때문에 가격 변동이 있을 수 있으며, AWS가 해당 용량을 필요로 할 경우 학습 작업이 중단될 수 있다는 특징이 있습니다. 하지만 SageMaker는 이러한 중단 가능성을 자동으로 처리하고, 중단 지점부터 학습을 재개할 수 있는 기능을 제공하여 개발자들이 큰 부담 없이 Spot 인스턴스를 활용할 수 있도록 지원합니다.
Spot Training을 효과적으로 활용하기 위해서는 학습 중간에 모델 가중치와 옵티마이저 상태를 저장하는 체크포인팅(Checkpointing) 전략이 필수적입니다. SageMaker는 학습 중단 시 자동으로 체크포인트를 S3에 저장하고, 재개 시 이를 로드하여 학습을 이어갈 수 있도록 설계되었습니다. 이를 통해 불시에 학습이 중단되더라도 이전 학습 상태를 잃지 않고 효율적으로 작업을 완료할 수 있습니다. 2026년 4월 현재, AWS는 Spot 인스턴스의 안정성을 지속적으로 개선하고 있으며, 특정 리전에 따라 중단 빈도가 낮아져 대규모 모델 학습에도 점차 더 유리한 환경을 제공하고 있습니다.
다음은 SageMaker Python SDK를 사용하여 Spot Training을 설정하는 구체적인 코드 예시입니다. Estimator 인스턴스 생성 시 use_spot_instances=True와 max_wait_time, max_run 파라미터를 설정하여 Spot Training을 활성화할 수 있습니다. max_wait_time은 인스턴스를 기다리는 최대 시간이며, max_run은 전체 학습 작업의 최대 실행 시간입니다. 더 자세한 내용은 AWS SageMaker Python SDK 공식 문서에서 확인할 수 있습니다. 만약 AI 프로젝트의 전반적인 클라우드 비용 최적화에 관심이 있다면, 저희 블로그의 2025년 AI FinOps 전략 및 최적화 툴 3대장 글도 참고해 보세요.
import sagemaker
from sagemaker.pytorch import PyTorch
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
# Spot Training을 위한 Estimator 설정
estimator = PyTorch(
entry_point='train.py',
source_dir='./src',
role=role,
instance_count=1,
instance_type='ml.g4dn.xlarge', # 원하는 GPU 인스턴스 타입
framework_version='1.13.1',
py_version='py39',
hyperparameters={
'epochs': 10,
'batch-size': 64,
'learning-rate': 0.001
},
use_spot_instances=True, # Spot Training 활성화
max_wait_time=3600, # Spot 인스턴스를 기다리는 최대 시간 (초, 1시간)
max_run=7200, # 전체 학습 작업의 최대 실행 시간 (초, 2시간)
checkpoint_s3_uri=f's3://{sagemaker_session.default_bucket()}/checkpoints/', # 체크포인트 S3 경로
# metric_definitions=[{'Name': 'validation:loss', 'Regex': 'val_loss=(.*?);'}], # 학습 메트릭 정의
# enable_sagemaker_metrics=True
)
# 학습 시작
# estimator.fit({'training': 's3://your-data-bucket/train/', 'validation': 's3://your-data-bucket/val/'})
대규모 모델 학습 시간 30% 단축: SageMaker 분산 학습 활용법
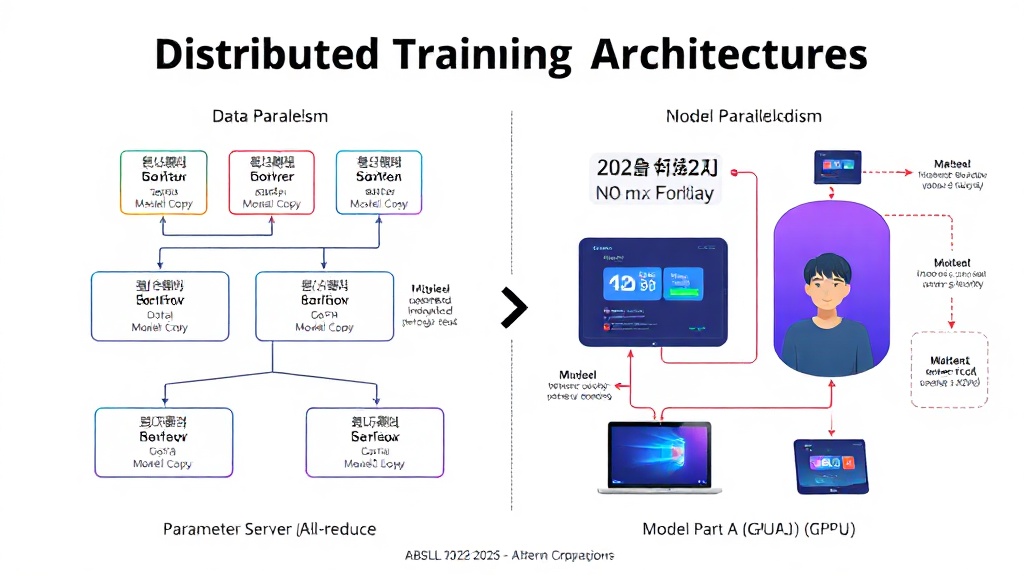
대규모 머신러닝 모델을 학습시킬 때 단일 GPU의 성능만으로는 충분하지 않은 경우가 많습니다. 이때 여러 GPU나 여러 인스턴스에 학습 작업을 분할하여 처리하는 분산 학습(Distributed Training)이 필수적입니다. 분산 학습은 크게 데이터 병렬화(Data Parallelism)와 모델 병렬화(Model Parallelism)로 나눌 수 있습니다. 데이터 병렬화는 각 장치에 데이터의 일부를 나누어 처리하고, 그라디언트를 동기화하여 모델을 업데이트하는 방식이며, 모델 병렬화는 모델 자체를 여러 장치에 분할하여 배치하는 방식입니다. OpenAI와 Anthropic 같은 선두 AI 기업들은 수백 개의 GPU를 활용한 분산 학습으로 수천억 개 파라미터를 가진 LLM을 훈련하고 있습니다.
AWS SageMaker는 분산 학습을 쉽게 구현할 수 있도록 SageMaker Distributed Data Parallel (SMDDP)과 SageMaker Model Parallel (SMP) 라이브러리를 제공합니다. SMDDP는 PyTorch DistributedDataParallel(DDP)의 성능을 향상시키고 AWS 네트워크 인프라에 최적화되어, 통신 오버헤드를 줄여줍니다. SMP는 대규모 모델이 단일 GPU 메모리에 들어가지 않을 때 모델 파트를 여러 GPU에 걸쳐 분할하여 학습할 수 있도록 돕습니다. 2025년 기준으로, SageMaker의 분산 학습 기능은 지속적으로 발전하여, 복잡한 설정 없이도 높은 효율성을 제공합니다.
다음은 SageMaker Python SDK를 사용하여 분산 학습을 설정하는 코드 예시입니다. instance_count를 1보다 크게 설정하고 distribution 파라미터를 통해 SageMaker Distributed Data Parallel을 활성화할 수 있습니다. 이를 통해 여러 GPU 인스턴스에 걸쳐 학습 작업을 병렬로 실행하여 학습 시간을 최대 30% 이상 단축할 수 있습니다. 특히 sagemaker.pytorch.PyTorch Estimator는 distribution={'smd_dataloader': {'enabled': True}}와 같은 설정을 통해 데이터 로딩까지 최적화할 수 있어, I/O 병목 현상을 줄이는 데 기여합니다. 더 많은 정보는 AWS SageMaker 분산 학습 개발자 가이드를 참고하세요.
import sagemaker
from sagemaker.pytorch import PyTorch
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
# 분산 학습을 위한 Estimator 설정
estimator = PyTorch(
entry_point='train.py',
source_dir='./src',
role=role,
instance_count=2, # 2개의 인스턴스 사용
instance_type='ml.g4dn.xlarge', # 각 인스턴스에 GPU 포함
framework_version='1.13.1',
py_version='py39',
hyperparameters={
'epochs': 10,
'batch-size': 64,
'learning-rate': 0.001
},
# 분산 학습 설정 (SageMaker Distributed Data Parallel)
distribution={
'pytorchddp': {'enabled': True},
'smd_dataloader': {'enabled': True} # 데이터 로딩 최적화
}
)
# 학습 시작
# estimator.fit({'training': 's3://your-data-bucket/train/', 'validation': 's3://your-data-bucket/val/'})
비용 절감 및 효율 극대화를 위한 최적화 전략: Spot + 분산 학습 결합
AWS SageMaker Spot Training과 분산 학습을 함께 사용하면 ML 학습 비용을 획기적으로 절감하고 학습 효율을 극대화할 수 있습니다. Spot 인스턴스의 저렴한 가격 이점과 분산 학습의 빠른 처리 속도를 결합하면 대규모 모델을 더욱 경제적이고 신속하게 훈련할 수 있습니다. 하지만 두 가지 기술을 결합할 때는 몇 가지 주의할 점이 있습니다. Spot 인스턴스는 언제든지 중단될 수 있으므로, 분산 학습 환경에서 체크포인팅 전략을 더욱 견고하게 구축해야 합니다. SageMaker는 이를 위해 SMDDP Elastic과 같은 기능을 제공하여, 중단 후에도 학습 노드를 유연하게 조절하며 재개할 수 있도록 돕습니다.
또한, 인스턴스 타입 선택도 중요합니다. 분산 학습의 효율은 네트워크 대역폭에 크게 의존하므로, 네트워크 성능이 우수한 인스턴스 타입(예: ml.g4dn, ml.p3, ml.p4d 계열)을 선택하는 것이 중요합니다. 2025년 기준, AWS는 더욱 강력한 네트워크 성능을 가진 인스턴스들을 지속적으로 출시하고 있습니다. TechCrunch 2024년 기사에 따르면, 클라우드 비용 최적화는 2025년 주요 기술 트렌드 중 하나이며, 특히 ML 워크로드에서 리소스 효율성이 더욱 강조될 것으로 전망됩니다.
다음은 ML 학습에 사용되는 인스턴스 유형별 특징과 비용 효율성을 비교한 표입니다. Spot 인스턴스는 높은 비용 절감 효과를 제공하지만, 중단 가능성을 고려한 학습 설계가 필요합니다. 온디맨드 인스턴스는 안정적이지만 비용이 높고, 예약 인스턴스는 장기 약정 시 비용을 절감할 수 있으나 유연성이 떨어집니다. 이 표는 대략적인 비용 효율성을 나타내며, 실제 비용은 지역, 인스턴스 유형, 사용량에 따라 달라질 수 있습니다.
| 특징 | Spot 인스턴스 | 온디맨드 인스턴스 | 예약 인스턴스 (RI) |
|---|---|---|---|
| 비용 절감 | 최대 90% (가장 높음) | 없음 | 20~70% (장기 약정 시) |
| 안정성 | 낮음 (중단 가능성) | 높음 | 높음 |
| 유연성 | 높음 (단기 사용 적합) | 높음 | 낮음 (장기 약정) |
| 적합한 워크로드 | 내결함성 있는 ML 학습, 배치 처리 | 중단 없이 실행되어야 하는 중요 작업 | 지속적이고 예측 가능한 ML 학습 |
| SageMaker 지원 | Spot Training으로 지원 | 기본 지원 | SageMaker 예약 인스턴스 |
결론적으로, 대규모 ML 모델 학습 시 비용을 50% 절감하고 리소스 효율을 2배 향상시키려면 SageMaker Spot Training과 분산 학습을 결합하는 것이 최적의 전략입니다. 이를 위해 체크포인팅을 통해 학습 중단에 대비하고, 네트워크 성능이 좋은 인스턴스를 선택하며, 모델과 데이터의 특성에 맞는 분산 학습 전략(데이터 병렬화 또는 모델 병렬화)을 수립하는 것이 중요합니다. 핵심 요약:
- 비용 절감: AWS SageMaker Spot Training으로 ML 학습 비용 최대 90% 절감.
- 학습 시간 단축: SageMaker 분산 학습으로 대규모 모델 학습 시간 30% 단축.
- 리소스 효율: 두 기술 결합 시 리소스 효율 2배 향상.
- 필수 전략: 강력한 체크포인팅, 네트워크 최적화 인스턴스 선택.
- 적용 범위: LLM, 이미지 모델 등 대규모 AI 워크로드에 최적.

자주 묻는 질문
Q. SageMaker Spot Training 사용 시 학습 중단이 너무 잦으면 어떻게 해야 하나요?
A. 학습 중단이 잦다면 max_wait_time을 늘리거나, 체크포인팅 간격을 줄여 손실되는 작업량을 최소화해야 합니다. 또한, 특정 시간대에 Spot 인스턴스 가용성이 낮을 수 있으므로 다른 시간대에 시도하거나, 온디맨드 인스턴스와 Spot 인스턴스를 혼합하여 사용하는 전략을 고려할 수 있습니다. sagemaker.workflow.steps.TrainingStep 같은 SageMaker Pipeline을 활용하여 학습 중단 시 재시도 로직을 자동화할 수도 있습니다.
Q. 분산 학습 시 데이터 병렬화와 모델 병렬화 중 어떤 것을 선택해야 하나요? A. 대부분의 경우 데이터 병렬화(Data Parallelism)가 더 구현하기 쉽고 효율적입니다. 모델이 단일 GPU 메모리에 들어갈 정도로 크지만 학습 시간이 오래 걸릴 때 적합합니다. 반면, 모델 자체가 너무 커서 단일 GPU 메모리에 들어가지 않는 초거대 모델(예: 수백억 개 이상의 파라미터) 학습에는 모델 병렬화(Model Parallelism)가 필수적입니다. SageMaker Model Parallel (SMP) 라이브러리를 사용하면 복잡한 모델 분할을 비교적 쉽게 처리할 수 있습니다.
Q. SageMaker Spot Training과 분산 학습을 함께 사용할 때 어떤 이점을 기대할 수 있나요? A. 두 기술을 함께 사용하면 학습 비용을 최대 50% 이상 절감하면서도 대규모 모델의 학습 시간을 30% 이상 단축할 수 있습니다. 예를 들어, 온디맨드 인스턴스로 10시간 걸리던 분산 학습 작업이 Spot 인스턴스를 활용하면 같은 시간 내에 훨씬 저렴한 비용으로 완료될 수 있습니다. 중요한 것은 SageMaker가 Spot 인스턴스 중단과 분산 학습 환경을 자동으로 관리해 주므로, 개발자는 복잡한 인프라 관리에 신경 쓸 필요 없이 모델 개발에 집중할 수 있다는 점입니다.
참고자료
- How Training Works - AWS SageMaker Developer Guide (2024)
- Distributed Training on Amazon SageMaker - AWS (2024)
- The state of AI in 2023: Generative AI’s breakout year - McKinsey (2023)
- Gartner Hype Cycle for AI, 2024 - Gartner (2024)
- Cloud cost optimization trends for 2025 - TechCrunch (2024)
이 글이 도움이 되셨다면 공유해 주세요.


