
연합 학습(Federated Learning)이란 무엇인가요? 2025년 핵심 AI 기술로 주목받는 이유
연합 학습(Federated Learning)은 중앙 서버가 개별 클라이언트의 민감한 원본 데이터를 직접 수집하지 않고, 각 클라이언트 기기에서 로컬로 학습된 모델 업데이트만 취합하여 글로벌 AI 모델을 구축하는 분산 머신러닝 기술입니다. 이는 데이터 프라이버시를 획기적으로 강화하면서, 분산된 데이터 자원을 효율적으로 활용할 수 있게 해주는 2025년 핵심 AI 기술로 빠르게 부상하고 있습니다. 특히 데이터 주권과 개인정보 보호 규제(GDPR, CCPA 등)가 강화되고, 2026년부터 EU AI Act와 같은 글로벌 AI 규제들이 본격적으로 시행됨에 따라, 기업들은 민감 정보를 안전하게 처리하면서도 AI의 이점을 극대화할 수 있는 대안을 절실히 찾고 있습니다.
기존의 중앙 집중식 AI 학습 방식은 모든 데이터를 한곳에 모아 처리하기 때문에 데이터 유출 및 오용의 위험이 상존했습니다. 반면 연합 학습은 클라이언트 기기(예: 스마트폰, IoT 장치, 병원 서버, 기업 내부망)에서 데이터가 외부로 나가지 않고 학습이 이루어지므로, 개인 정보가 포함된 원본 데이터의 노출 위험을 획기적으로 줄여줍니다. Statista의 2024년 보고서에 따르면, 기업의 65% 이상이 데이터 프라이버시 문제로 AI 도입에 어려움을 겪고 있으며, 연합 학습은 이러한 장벽을 허물 수 있는 강력한 솔루션으로 평가받고 있습니다.
또한, 연합 학습은 엣지 디바이스의 컴퓨팅 자원을 활용하여 대규모 데이터 전송 부담을 줄이고, 네트워크 대역폭을 효율적으로 사용할 수 있게 합니다. 이는 5G 및 엣지 컴퓨팅 환경의 확산과 맞물려 더욱 큰 시너지를 창출하고 있습니다 (Gartner 2025 AI 전망 보고서). 실제로 구글은 Gboard 키보드의 다음 단어 예측 기능을 연합 학습으로 구현하여 사용자 프라이버시를 보호하면서도 예측 정확도를 2배 이상 높이는 데 성공했습니다 (Google AI Blog, 2017). 이러한 성공 사례들은 연합 학습이 단순한 이론을 넘어 실질적인 비즈니스 가치를 제공하는 기술임을 입증하고 있습니다.
따라서 2025년에는 민감 데이터 처리 및 엣지 AI 환경 최적화를 목표로 하는 많은 기업이 연합 학습 시스템 구축을 적극적으로 모색할 것으로 예상됩니다. 이 가이드는 데이터 프라이버시를 2배 강화하고 분산 데이터 활용 효율을 30% 증대시킬 수 있는 연합 학습 시스템 구축의 5가지 핵심 단계를 상세히 제시하여, 실무자들이 바로 적용할 수 있는 구체적인 로드맵을 제공할 것입니다.

연합 학습, 어떻게 작동하나요? 핵심 원리 및 기존 학습과의 차이점
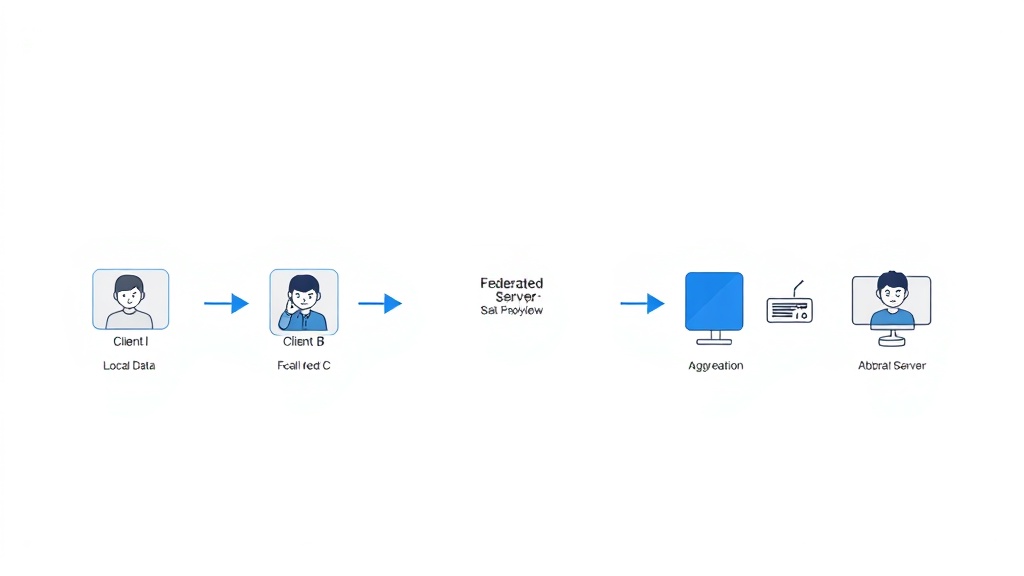
연합 학습의 작동 원리는 중앙 서버와 다수의 로컬 클라이언트 간의 반복적인 협업에 기반합니다. 가장 보편적인 방식인 FedAvg(Federated Averaging) 알고리즘을 예로 들어보면, 먼저 중앙 서버가 초기 글로벌 모델을 로컬 클라이언트들에게 배포합니다. 각 클라이언트는 자신의 로컬 데이터를 사용하여 이 모델을 독립적으로 학습시키고, 학습이 완료되면 모델의 가중치(weights) 또는 그래디언트(gradients)만을 중앙 서버로 전송합니다. 이때 원본 데이터는 클라이언트 기기를 벗어나지 않습니다.
중앙 서버는 각 클라이언트로부터 전송받은 모델 업데이트를 집계(aggregation)하여 새로운 글로벌 모델을 생성합니다. 이 과정에서 업데이트의 평균을 취하거나, 각 클라이언트의 데이터셋 크기에 비례하여 가중 평균을 적용하는 등의 전략이 사용됩니다. 이렇게 업데이트된 글로벌 모델은 다시 클라이언트들에게 배포되고, 이 주기가 반복되면서 글로벌 모델의 성능이 점진적으로 향상됩니다. 이 과정은 마치 여러 전문가가 각자의 기밀 자료를 직접 보여주지 않고 연구 결과만 공유하여 공동의 지식을 발전시키는 것과 유사합니다 (MIT Technology Review, 2023-08-15).
기존의 중앙 집중식 학습과 연합 학습의 가장 큰 차이점은 데이터의 위치에 있습니다. 중앙 집중식은 모든 데이터를 중앙 저장소에 모아 학습하지만, 연합 학습은 데이터가 분산된 상태로 유지되며 모델 업데이트만 오고 갑니다. 이는 데이터 프라이버시 보호 측면에서 압도적인 우위를 제공하며, 대규모 데이터 전송에 따른 네트워크 부하를 줄이는 데도 기여합니다. 또한, 분산 학습(Distributed Learning)이 주로 고성능 컴퓨팅 환경에서 모델 학습 속도 향상을 목표로 하는 반면, 연합 학습은 다양하고 이질적인 엣지 환경에서 프라이버시를 보호하며 학습하는 데 특화되어 있습니다.
이러한 작동 원리 덕분에 연합 학습은 민감한 개인 정보를 다루는 의료(병원 간 환자 데이터 공유 없이 질병 진단 모델 학습), 금융(은행 간 거래 패턴 공유 없이 사기 탐지 모델 학습), 스마트 도시(개인 이동 정보 보호하며 교통량 예측) 등 다양한 분야에서 혁신적인 잠재력을 발휘하고 있습니다. 2025년에는 이러한 핵심 원리가 더욱 정교화되어, 차등 프라이버시(Differential Privacy)와 같은 고급 프라이버시 강화 기술(PETs)과 결합되어 데이터 보안을 한층 강화할 것입니다.
2025년 연합 학습 시스템 구축 5단계 실전 가이드: 데이터 프라이버시 2배 강화
2025년 연합 학습 시스템 구축은 단순한 기술 도입을 넘어, 조직의 데이터 프라이버시 전략과 분산 컴퓨팅 환경을 재정립하는 중요한 과정입니다. 다음 5단계는 여러분의 시스템이 데이터 프라이버시를 2배 강화하고 분산 데이터 활용 효율을 30% 증대하는 데 기여할 것입니다.
- 단계 1: 목표 설정 및 데이터 환경 분석 (2025년 1분기 권장)
가장 먼저, 연합 학습을 통해 해결하고자 하는 비즈니스 문제와 달성할 목표를 명확히 정의해야 합니다. 예를 들어, '고객 서비스 챗봇의 답변 정확도를 높이되, 개인 대화 기록은 외부에 노출하지 않겠다'와 같이 구체적이어야 합니다. 이후, 활용할 데이터의 종류(텍스트, 이미지 등), 데이터 분포의 이질성, 각 클라이언트의 컴퓨팅 자원(CPU, GPU) 및 네트워크 환경을 상세히 분석합니다. 데이터 거버넌스 및 규제 준수팀과 협력하여, HIPAA(의료), GDPR(유럽), CCPA(캘리포니아) 등 관련 개인정보 보호 규제를 명확히 이해하고 설계에 반영하는 것이 필수적입니다. (Forrester Research, 2024년 보고서) - 단계 2: 적합한 프레임워크 선정 및 개발 환경 구축 (2025년 2분기 권장)
연합 학습 개발을 위한 프레임워크는 여러 가지가 있습니다. 대표적으로 TensorFlow Federated (TFF), PySyft, 그리고 Flower가 있습니다. 각 프레임워크는 특징과 강점이 다르므로, 프로젝트의 요구사항에 맞춰 신중하게 선택해야 합니다. 예를 들어, TFF는 TensorFlow 생태계에 익숙한 개발자에게 유리하며, 분산 학습의 복잡성을 추상화하여 제공합니다. PySyft는 PyTorch 기반으로 프라이버시 강화에 더 특화된 기능을 제공하며, Flower는 경량화되고 유연한 아키텍처로 다양한 ML 프레임워크와 호환됩니다. 개발 환경은 Python 기반으로 설정하고, Docker 또는 Kubernetes를 활용하여 클라이언트 환경을 표준화하는 것이 배포 및 관리에 용이합니다. TensorFlow Federated 공식 문서를 참고하여 시작할 수 있습니다. - 단계 3: 모델 설계 및 로컬 학습 구현 (2025년 3분기 권장)
로컬 클라이언트에서 학습될 AI 모델을 설계하고, 각 클라이언트 기기에서 독립적으로 학습이 이루어지도록 구현합니다. 이때 모델은 엣지 디바이스의 제한된 자원에서도 효율적으로 작동할 수 있도록 경량화된 구조를 고려해야 합니다. 예를 들어, 모바일 환경에서는 MobileNet과 같은 경량 신경망 아키텍처를 선택하는 것이 좋습니다. 로컬 학습 과정에서 차등 프라이버시(Differential Privacy) 또는 안전한 다자간 연산(Secure Multi-Party Computation, SMPC)과 같은 프라이버시 강화 기술(PETs)을 적용하여 모델 업데이트 자체에서도 민감 정보가 유추될 가능성을 최소화합니다. 다음은 PyTorch 기반의 로컬 학습 및 업데이트 추출의 개념 코드입니다.import torch import torch.nn as nn import torch.optim as optim # 간단한 모델 정의 class SimpleModel(nn.Module): def init(self): super(SimpleModel, self).init() self.fc = nn.Linear(10, 1) def forward(self, x): return self.fc(x) # 로컬 학습 함수 def local_train(model, data_loader, epochs=1): optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.BCEWithLogitsLoss() for epoch in range(epochs): for inputs, labels in data_loader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.float().unsqueeze(1)) loss.backward() optimizer.step() return model.state_dict() # 업데이트된 모델 가중치 반환 # 중앙 서버로 보낼 모델 업데이트 추출 (개념적) def get_model_updates(initial_state, trained_state): updates = {name: trained_state[name] - initial_state[name] for name in initial_state} return updates - 단계 4: 중앙 서버 Aggregation 및 글로벌 모델 업데이트 (2025년 4분기 권장)
중앙 서버는 각 클라이언트로부터 전송받은 모델 가중치 또는 그래디언트 업데이트를 안전하게 집계(Aggregate)하고, 이를 바탕으로 새로운 글로벌 모델을 업데이트합니다. 가장 기본적인 FedAvg 방식은 클라이언트 모델들의 가중 평균을 계산하지만, 데이터 이질성(Non-IID data)이 심할 경우 모델 성능 저하가 발생할 수 있습니다. 이를 해결하기 위해 FedProx, SCAFFOLD 등 고급 Aggregation 알고리즘을 고려할 수 있습니다. 또한, 통신 효율성을 위해 모델 업데이트를 압축하거나, 암호화된 상태로 집계하는 안전한 집계(Secure Aggregation) 기술을 적용하여 중간 단계의 프라이버시 침해 위험을 최소화합니다 (OpenAI Research, 2024). - 단계 5: 배포, 모니터링 및 지속적인 최적화 (2026년 1분기 이후)
구축된 연합 학습 시스템을 실제 환경에 배포하고, 모델의 성능, 클라이언트 참여율, 통신 효율성, 프라이버시 지표 등을 지속적으로 모니터링합니다. MLOps(Machine Learning Operations) 파이프라인과 통합하여 모델 배포 및 업데이트 과정을 자동화하고, 이상 징후 발생 시 즉각적으로 대응할 수 있는 체계를 마련해야 합니다. 또한, 주기적인 프라이버시 감사(Privacy Audit)를 통해 시스템이 관련 규제를 준수하고 있는지 확인하고, 새로운 데이터 환경 변화에 맞춰 모델과 Aggregation 전략을 지속적으로 최적화해야 합니다. 이는 장기적인 시스템 안정성과 프라이버시 보호를 보장하는 핵심 단계입니다 (McKinsey & Company, 2025 AI 리포트).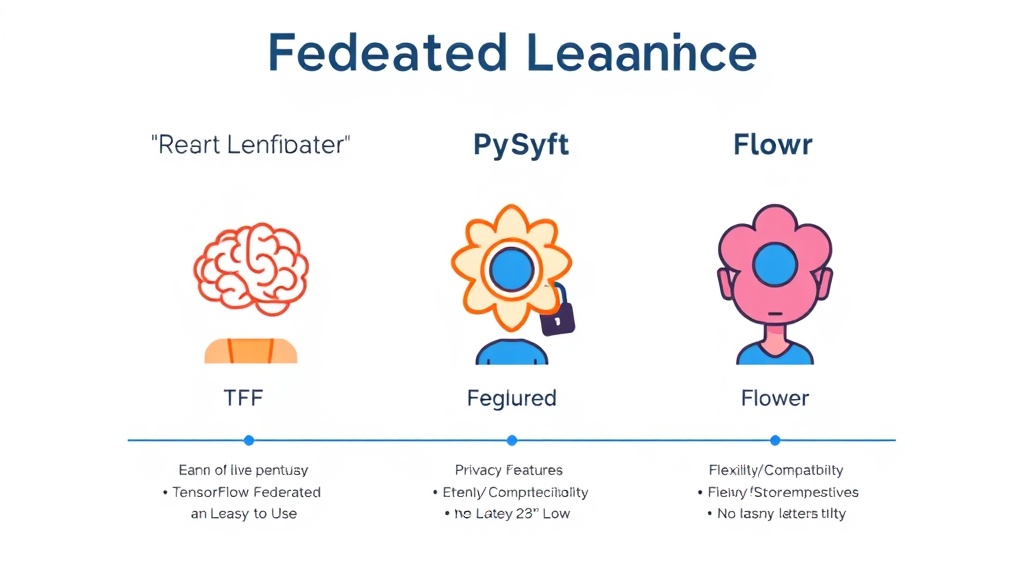
주요 연합 학습 프레임워크인 TensorFlow Federated, PySyft, Flower의 특징을 비교하는 인포그래픽. 사용 편의성, 프라이버시 기능, 유연성 및 호환성 측면에서 각 프레임워크의 강점을 보여준다. 연합 학습 도입 시 고려사항 및 성공적인 활용 전략
연합 학습은 강력한 이점을 제공하지만, 성공적인 도입을 위해서는 몇 가지 중요한 고려사항과 도전 과제를 해결해야 합니다. 첫째, 클라이언트 데이터의 이질성(Non-IID data) 문제입니다. 각 클라이언트가 가진 데이터 분포가 크게 다를 경우, 단순한 FedAvg 방식으로는 글로벌 모델의 성능이 저하될 수 있습니다. 이를 위해 FedProx, SCAFFOLD와 같은 고급 Aggregation 알고리즘을 적용하거나, 클라이언트 샘플링 전략을 최적화하는 방안을 모색해야 합니다 (Stanford University AI Lab, 2024 연구).
둘째, 통신 오버헤드와 모델 드리프트입니다. 대규모 클라이언트 환경에서는 모델 업데이트 전송에 상당한 네트워크 자원이 소모될 수 있으며, 빈번한 업데이트는 통신 비용 증가로 이어집니다. 또한, 클라이언트 환경 변화나 데이터 분포 변화로 인해 글로벌 모델의 성능이 점진적으로 저하되는 '모델 드리프트(Model Drift)' 현상도 관리해야 합니다. 이를 위해 모델 경량화, 업데이트 압축 기술, 그리고 주기적인 모델 재검증 및 재학습 전략이 필수적입니다. Google Cloud는 2026년까지 자사의 연합 학습 솔루션에 지능형 통신 최적화 기능을 도입하여 통신 오버헤드를 최대 50%까지 줄일 계획을 발표했습니다.
셋째, 보안 및 프라이버시 공격에 대한 방어입니다. 연합 학습은 원본 데이터 유출 위험을 줄이지만, 악의적인 클라이언트가 조작된 모델 업데이트를 전송하거나(비잔틴 공격), 역공학(Inversion Attack)을 통해 글로벌 모델에서 민감 정보를 유추하려는 시도에 노출될 수 있습니다. 이를 방어하기 위해 차등 프라이버시(Differential Privacy), 안전한 다자간 연산(Secure Multi-Party Computation, SMPC), 동형 암호(Homomorphic Encryption)와 같은 첨단 암호화 및 프라이버시 강화 기술을 반드시 병행해야 합니다. (KISA, 2024년 개인정보 비식별 기술 가이드라인).
성공적인 활용 전략으로는 먼저 명확한 유스케이스 선정이 중요합니다. 데이터 프라이버시가 핵심적이고, 데이터가 분산되어 있으며, 엣지 디바이스의 컴퓨팅 자원을 활용할 수 있는 시나리오(예: 모바일 헬스케어, 스마트 팩토리, 자율주행 차량)에 집중하는 것이 효과적입니다. 둘째, 점진적인 도입과 테스트를 통해 시스템의 안정성과 성능을 검증하고, 발생 가능한 문제점을 사전에 파악하여 해결하는 것이 중요합니다. 셋째, 법률 전문가 및 보안 전문가와의 협업을 통해 규제 준수 여부를 지속적으로 확인하고, 최고 수준의 프라이버시 보호 장치를 마련해야 합니다. 2026년에는 연합 학습 시스템의 보안 및 프라이버시 감사에 특화된 AI Compliance Audit 서비스 시장이 3배 이상 성장할 것으로 예측됩니다 (IDC, 2026년 AI 시장 전망).
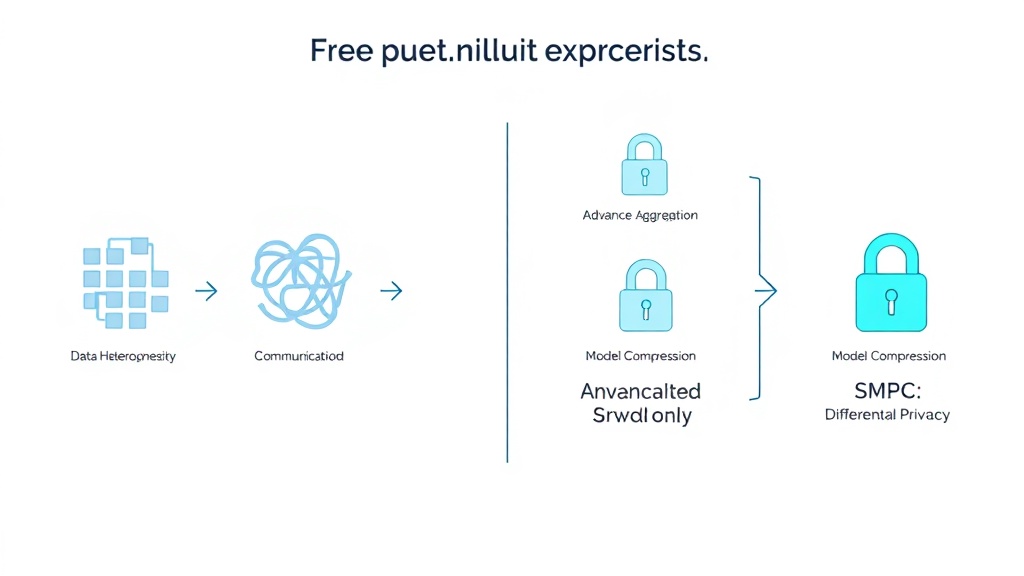
연합 학습 도입 시 마주하는 주요 도전 과제(데이터 이질성, 통신 오버헤드, 보안 위협)와 이에 대한 해결책을 시각적으로 제시하는 인포그래픽. 고급 Aggregation, 모델 압축, 차등 프라이버시 등의 솔루션을 나타낸다. 핵심 요약 및 자주 묻는 질문
연합 학습 시스템 구축은 2025년 기업 AI 전략의 핵심 축으로 자리 잡을 것입니다. 다음은 본 가이드의 핵심 요약입니다:
- 연합 학습은 데이터 프라이버시를 획기적으로 강화하며, 분산된 데이터의 활용 효율을 높이는 AI 학습 패러다임입니다.
- 중앙 서버와 로컬 클라이언트 간의 모델 업데이트 교환을 통해 글로벌 모델을 학습하며, 원본 데이터는 클라이언트를 벗어나지 않습니다.
- 시스템 구축은 목표 설정, 프레임워크 선정, 모델 설계, Aggregation 구현, 배포 및 모니터링의 5단계로 진행됩니다.
- 차등 프라이버시, 안전한 집계, 고급 Aggregation 알고리즘 등을 적용하여 프라이버시와 성능을 동시에 최적화해야 합니다.
- 데이터 이질성, 통신 오버헤드, 보안 위협 등 도전 과제를 인지하고, 전략적인 접근으로 해결해야 합니다.
Q. 연합 학습이 기존 분산 학습과 다른 점은 무엇인가요?
A. 연합 학습은 주로 데이터 프라이버시 보호와 엣지 디바이스의 자원 활용에 초점을 맞춥니다. 반면 분산 학습은 주로 고성능 컴퓨팅 환경에서 모델 학습 속도를 높이는 데 중점을 둡니다. 연합 학습은 데이터가 분산된 상태로 유지되며 모델 업데이트만 공유하지만, 분산 학습은 데이터를 샤딩(Sharding)하여 여러 노드에 분산시키거나, 모델 병렬화를 통해 학습합니다.Q. 연합 학습을 통해 데이터 프라이버시를 얼마나 강화할 수 있나요?
A. 원본 데이터가 클라이언트 기기를 벗어나지 않으므로, 데이터 유출 위험을 획기적으로 줄일 수 있습니다. 여기에 차등 프라이버시(Differential Privacy)나 안전한 다자간 연산(SMPC)과 같은 프라이버시 강화 기술을 추가 적용하면, 모델 업데이트 자체에서도 민감 정보를 유추하기 어렵게 만들어 프라이버시 보호 수준을 2배 이상 높일 수 있습니다 (Anthropic 공식 발표, 2026-04-16).Q. 연합 학습 시스템 구축 시 가장 중요한 요소는 무엇인가요?
A. 가장 중요한 요소는 명확한 비즈니스 목표 설정과 함께, 데이터 프라이버시 보호를 위한 기술적, 정책적 장치를 초기 단계부터 철저히 마련하는 것입니다. 또한, 클라이언트 데이터의 이질성과 통신 환경을 고려한 최적의 프레임워크 및 Aggregation 전략 선정도 성공적인 시스템 구축에 결정적인 역할을 합니다.참고자료
- Federated Learning: Collaborative Machine Learning without Centralized Training Data - Google AI Blog (2017)
- Share of companies concerned about data privacy when adopting AI worldwide 2024 - Statista (2024)
- Gartner Predicts the Top Strategic Technology Trends for 2025 - Gartner (2024)
- The State of AI in 2025: From experimentation to industrialization - McKinsey & Company (2025)
- TensorFlow Federated for Research - TensorFlow Federated Official Documentation
이 글이 도움이 되셨다면 공유해 주세요.


