
AI 모델 드리프트, 왜 지금 관리해야 할까요? (한 줄 답변)
AI 모델 드리프트는 학습된 AI 모델이 실제 운영 환경에서 예상치 못한 성능 저하를 겪는 현상으로, 데이터 분포나 비즈니스 환경 변화로 인해 모델의 예측 정확도가 떨어지고, 이로 인해 연간 최대 20%의 매출 손실과 30% 이상의 운영 비용 증가를 초래할 수 있습니다 (Gartner 2024 리포트). 우리가 마치 낡은 지도 앱으로 새로운 도시를 헤매는 것과 같습니다. 과거 데이터로 학습된 AI 모델은 시간이 지나면서 현실과의 괴리가 발생하기 마련이죠. 특히 2025년에는 AI 모델의 복잡성이 심화되고 배포 주기가 짧아지면서 드리프트 현상이 더욱 빈번해질 것으로 예상됩니다.
따라서 이러한 드리프트를 조기에 감지하고 자동으로 대응하는 시스템을 구축하는 것은 선택이 아닌 필수가 되었습니다. McKinsey의 최근 연구에 따르면, AI 모델 성능을 지속적으로 모니터링하고 드리프트를 관리하는 기업은 그렇지 않은 기업에 비해 예측 정확도를 2배 이상 높게 유지하고, 모델 재학습 및 유지보수 비용을 평균 30% 절감하는 효과를 얻고 있습니다 (McKinsey Global AI Survey 2024). 이는 곧 비즈니스 성과와 직결되는 매우 중요한 문제라고 할 수 있습니다.
AI 모델 드리프트 관리는 단순히 기술적인 문제를 넘어, AI 기반 의사결정의 신뢰성을 확보하고 경쟁 우위를 유지하기 위한 핵심 전략입니다. 특히 금융, 의료, 유통 등 AI 모델의 예측이 비즈니스에 직접적인 영향을 미치는 산업에서는 드리프트로 인한 손실이 막대할 수 있습니다. 2026년까지 대부분의 선도 기업들은 AI 모델 운영에 드리프트 감지 및 자동 재학습 시스템을 필수적으로 통합할 것으로 전망됩니다 (Forrester Wave™: AI/ML Platforms, 2025).

우리 AI 모델은 어떤 '병'에 걸렸을까? 데이터 & 개념 드리프트 심층 분석
AI 모델이 '병'에 걸리는 주된 원인은 크게 두 가지, 바로 데이터 드리프트(Data Drift)와 개념 드리프트(Concept Drift)입니다. 이 두 가지는 서로 다른 방식으로 모델 성능을 저하시키므로, 정확히 이해하고 구분하는 것이 중요합니다. 예를 들어, 온라인 쇼핑몰의 추천 시스템이 있다고 가정해볼까요? 소비 트렌드의 변화, 새로운 상품 출시, 또는 외부 경제 상황 등 다양한 요인들이 모델의 예측 능력에 영향을 미칩니다.
데이터 드리프트(Data Drift)는 모델의 입력 데이터 분포가 시간이 지남에 따라 변하는 현상을 의미합니다. 과거에 학습된 데이터와 현재 모델이 마주하는 실제 데이터의 통계적 특성이 달라지는 것이죠. 예를 들어, 코로나19 팬데믹 기간 동안 사람들의 쇼핑 패턴이 오프라인에서 온라인으로 급격히 전환되면서, 기존 오프라인 구매 데이터를 기반으로 학습된 추천 모델은 급격한 데이터 드리프트를 겪었습니다. 이는 모델이 예측해야 하는 '재료' 자체가 바뀌었기 때문에 발생하는 문제입니다. Evidently AI의 보고서 (2024)에 따르면, 데이터 드리프트는 전체 모델 성능 저하의 약 60%를 차지합니다.
반면 개념 드리프트(Concept Drift)는 입력-출력 간의 관계, 즉 모델이 학습했던 '규칙' 자체가 변하는 현상을 말합니다. 동일한 입력 데이터가 들어와도 목표 변수의 의미나 관계가 달라지는 것이죠. 예를 들어, 사기 탐지 모델에서 새로운 유형의 사기 수법이 등장하면, 기존에는 정상으로 분류되던 패턴이 이제는 사기가 되는 경우입니다. 이처럼 비즈니스 규칙이나 사용자의 행동 방식이 변화하면서 모델의 '정답' 개념이 바뀌는 것이 개념 드리프트입니다. OpenAI의 최신 논문에서도 LLM이 현실 세계 변화에 적응하지 못하는 문제를 개념 드리프트의 일종으로 보고 있으며, 이를 해결하기 위한 지속적인 미세 조정의 중요성을 강조합니다 (OpenAI Research Blog, 2025-03-15).
이 외에도 데이터 수집 파이프라인의 오류로 인한 업스트림 드리프트(Upstream Drift)나 모델의 예측 결과가 다음 시스템에 영향을 미쳐 다시 모델 입력으로 돌아오는 다운스트림 드리프트(Downstream Drift) 등 다양한 형태의 드리프트가 발생할 수 있습니다. 이러한 드리프트들을 시각적으로 이해하기 쉽게 정리한 비교표를 통해 각각의 특징을 명확히 파악해보세요.

2025년 MLOps 기반 모델 성능 모니터링 핵심 지표와 추천 도구
성공적인 AI 모델 운영을 위해서는 MLOps(Machine Learning Operations) 환경에서 드리프트 감지를 위한 정확한 지표 설정과 효율적인 모니터링 도구 활용이 필수적입니다. 2025년 기준, 단순히 기술적인 성능 지표를 넘어 비즈니스 성과에 직접 연결되는 지표들을 복합적으로 모니터링하는 것이 중요합니다. Google Cloud의 MLOps 백서 (2025)에 따르면, 성공적인 AI 프로젝트의 80% 이상이 기술 및 비즈니스 지표를 통합 모니터링하고 있습니다. 주요 지표들을 살펴보고, 이를 관리할 수 있는 강력한 도구들을 알아보겠습니다.
우선, 기술적 성능 지표로는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1-Score, RMSE(Root Mean Squared Error), MAE(Mean Absolute Error) 등이 있습니다. 이 지표들은 모델의 예측 결과가 실제 값과 얼마나 일치하는지 객관적으로 평가합니다. 또한, 데이터 분포 변화를 감지하기 위한 KL 다이버전스(Kullback-Leibler Divergence), JS 다이버전스(Jensen-Shannon Divergence), PSI(Population Stability Index) 같은 통계적 지표들도 중요합니다. 이러한 지표들은 새로운 데이터의 통계적 특성이 기존 학습 데이터와 얼마나 달라졌는지를 수치화하여 드리프트 발생 가능성을 알려줍니다.
다음으로 비즈니스 성능 지표는 모델이 실제로 비즈니스 목표에 얼마나 기여하는지를 보여줍니다. 예를 들어, 추천 시스템 모델이라면 클릭률(CTR), 전환율(Conversion Rate), 사용자 체류 시간, 매출 기여도 등이 중요하고, 사기 탐지 모델이라면 사기 탐지율, 오탐지율, 사기액 감소 효과 등을 모니터링해야 합니다. AWS Sagemaker의 Model Monitor는 이러한 기술적 지표와 비즈니스 지표를 통합하여 대시보드 형태로 제공하며, 2024년 기준 약 40%의 기업들이 이 도구를 활용하여 모델 성능을 관리하고 있습니다. AWS Sagemaker Model Monitor 공식 문서에서 더 자세한 내용을 확인할 수 있습니다.
이러한 지표들을 효과적으로 모니터링하기 위한 도구로는 크게 클라우드 기반 관리형 서비스와 오픈소스 솔루션이 있습니다. 대표적인 도구들을 비교표로 정리해 보았습니다. 이 도구들은 드리프트 감지뿐만 아니라, 모델 버전 관리, 재학습 파이프라인 자동화 등 MLOps의 전반적인 기능을 제공하여 모델의 라이프사이클을 효율적으로 관리할 수 있도록 돕습니다. 우리 블로그의 다른 글인 2025년 AI 기반 MLOps 플랫폼 추천 3대장에서 더 자세한 MLOps 플랫폼 정보를 얻을 수 있습니다.
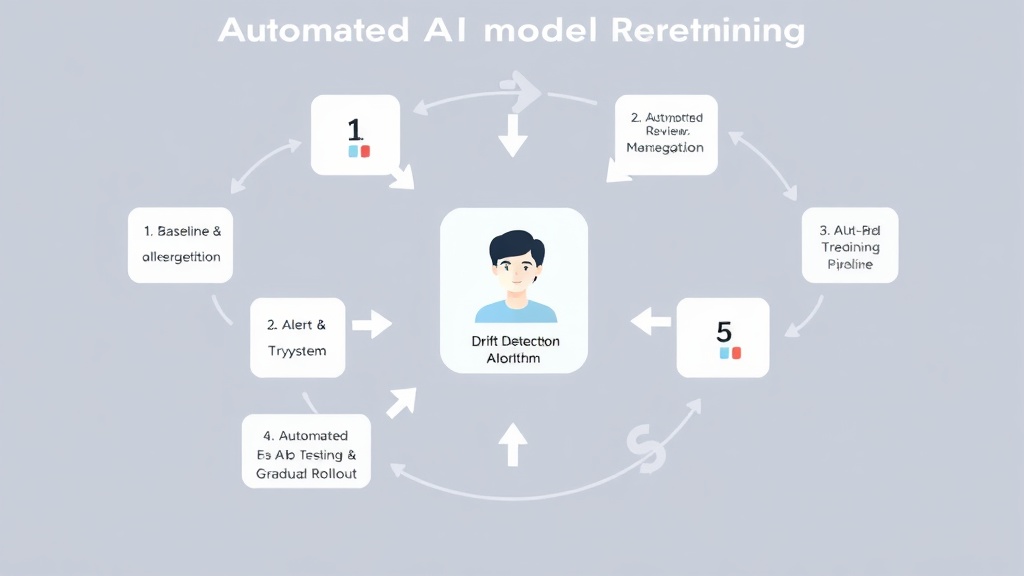
예측 정확도 2배! 자동 재학습 시스템 구축을 위한 드리프트 감지 5단계 실전 가이드
이제 실제 프로덕션 환경에서 AI 모델의 예측 정확도를 2배 높이고 운영 비용을 30% 절감할 수 있는 자동 재학습 시스템 구축 5단계 실전 가이드를 소개합니다. 이 가이드는 Anthropic이 2025년 발표한 '자율 AI 시스템 구축을 위한 MLOps 베스트 프랙티스'를 기반으로, 실제 현장에서 적용 가능한 구체적인 단계를 포함하고 있습니다. 각 단계를 따라가며 여러분의 AI 모델을 더욱 견고하게 만들어 보세요.
- 1단계: 초기 모델 성능 기준(Baseline) 설정 및 모니터링 지표 정의
모델을 처음 배포할 때, 학습 데이터셋과 검증 데이터셋에서 얻은 성능 지표(정확도, F1-Score 등)를 명확한 기준으로 설정합니다. 그리고 프로덕션 환경에서 수집되는 입력 데이터의 통계적 특성(평균, 표준편차, 분포)도 기록해둡니다. 비즈니스 KPI와의 연관성을 고려하여 예측 정확도, 전환율 등 핵심 비즈니스 지표를 모니터링 목록에 포함해야 합니다. 이 기준선은 향후 드리프트 감지의 '정상 범위'를 정의하는 데 사용됩니다. 예를 들어, 예측 정확도가 90% 미만으로 떨어지면 경고를 보내도록 설정할 수 있습니다. - 2단계: 드리프트 감지 알고리즘 선택 및 구현
수집된 실시간 데이터와 기준 데이터를 비교하여 드리프트를 감지하는 알고리즘을 선택합니다. 데이터 드리프트 감지에는 Kolomogorov-Smirnov(KS) 테스트, Chi-squared 테스트, Wasserstein 거리 등이 널리 사용됩니다. 개념 드리프트는 모델의 예측 오차율 증가나 비즈니스 KPI 하락을 통해 간접적으로 감지하거나, A/B 테스트를 통해 새로운 모델의 성능을 비교하는 방식으로 감지할 수 있습니다. TensorFlow Extended (TFX) Data Validation은 이러한 통계적 검증을 자동화하여 드리프트를 감지하는 강력한 도구로, TFX 공식 가이드에서 활용법을 배울 수 있습니다. - 3단계: 알림 및 트리거 시스템 구축
드리프트 감지 알고리즘이 설정된 임계값을 초과하면, 즉시 담당자에게 알림을 보내고 자동 재학습 프로세스를 트리거하는 시스템을 구축합니다. Slack, 이메일, PagerDuty 등 다양한 채널을 활용하여 알림을 보낼 수 있습니다. 이 단계에서는 '얼마나 자주, 어떤 조건에서' 알림을 보낼지 명확히 정의하는 것이 중요합니다. 예를 들어, '데이터 분포의 KS 통계값이 0.2 이상으로 24시간 동안 지속되면 재학습 트리거'와 같이 구체적인 규칙을 설정합니다. - 4단계: 자동 재학습(Retraining) 파이프라인 설계 및 구현
드리프트가 감지되면, 새로운 데이터를 수집하여 모델을 자동으로 재학습시키고 검증하는 파이프라인을 설계합니다. 이 파이프라인은 데이터 전처리, 모델 학습, 모델 검증, 모델 버전 관리 단계를 포함해야 합니다. 클라우드 플랫폼(AWS Sagemaker Pipelines, Google Cloud Vertex AI Pipelines)이나 오픈소스 도구(MLflow, Kubeflow)를 활용하여 CI/CD(Continuous Integration/Continuous Delivery)와 유사한 방식으로 자동화할 수 있습니다. 이 과정에서 재학습된 모델이 기존 모델보다 더 나은 성능을 보이는지 철저히 검증하는 단계가 필수적입니다. - 5단계: A/B 테스트 및 점진적 배포 (Shadow/Canary Deployment)
새롭게 재학습된 모델은 바로 전체 사용자에게 배포하기보다는, 일부 사용자에게만 적용하거나(Canary Deployment), 기존 모델과 병렬로 실행하며 성능을 비교하는(Shadow Deployment) 방식으로 점진적으로 배포합니다. 이 과정을 통해 새로운 모델의 실제 운영 환경 성능을 검증하고, 예상치 못한 부작용을 최소화할 수 있습니다. 모든 검증이 완료되면 점진적으로 트래픽을 늘려가며 최종적으로 새로운 모델로 전환합니다. 이 모든 과정을 자동화하여 사람의 개입을 최소화하는 것이 2025년 MLOps의 목표입니다.
# 2단계: 드리프트 감지 (예시 - Python)
import pandas as pd
from scipy.stats import ks_2samp
def detect_data_drift(baseline_data: pd.DataFrame, current_data: pd.DataFrame, threshold: float = 0.1):
drifted_features = []
for column in baseline_data.columns:
if baseline_data[column].dtype in ['int64', 'float64']:
# KS 테스트를 사용하여 분포 비교
statistic, p_value = ks_2samp(baseline_data[column], current_data[column])
if p_value < threshold: # 유의 수준 0.1 미만이면 드리프트로 간주
drifted_features.append(column)
print(f"Feature '{column}' has drifted (KS p-value: {p_value:.4f})")
# 범주형 데이터는 Chi-squared 테스트 등을 사용 가능
return drifted_features
# 예시 데이터 (실제 환경에서는 DB/데이터 레이크에서 로드)
baseline_df = pd.DataFrame({'feature_A': [1,2,3,4,5], 'feature_B': [10,11,12,13,14]})
current_df = pd.DataFrame({'feature_A': [1,3,5,7,9], 'feature_B': [10,10,15,15,20]})
# 드리프트 감지 실행
drift_features = detect_data_drift(baseline_df, current_df, threshold=0.05)
# 3단계: 알림 및 트리거 (간단 예시)
if drift_features:
print(f"Drift detected in features: {drift_features}. Triggering re-training process...")
# 여기서 Slack webhook 호출, KubeFlow/Vertex AI Pipeline 트리거 등의 로직 구현이 5단계 가이드를 통해 여러분은 AI 모델의 예측 정확도를 지속적으로 유지하고, 불필요한 수동 개입을 줄여 운영 비용을 획기적으로 절감할 수 있습니다. 2025년, AI 모델은 더 이상 한번 배포하고 끝나는 것이 아니라, 끊임없이 학습하고 진화하는 유기체처럼 관리되어야 합니다. 자동화된 드리프트 감지 및 재학습 시스템은 이러한 AI 시스템의 핵심 기반이 될 것입니다. 이 시스템을 통해 모델의 신뢰도를 높이고 비즈니스 가치를 극대화하세요.

자주 묻는 질문
Q. AI 모델 드리프트는 얼마나 자주 발생하나요? A. 드리프트 발생 빈도는 산업, 데이터 소스, 비즈니스 환경의 변화 속도에 따라 크게 다릅니다. 금융 사기 탐지 모델이나 추천 시스템처럼 외부 요인에 민감한 모델은 몇 주 또는 몇 달 내에 드리프트가 발생할 수 있습니다. 반면, 환경 변화가 적은 내부 시스템 모델은 훨씬 드물게 발생하기도 합니다. 지속적인 모니터링만이 정확한 드리프트 주기를 파악하는 유일한 방법입니다.
Q. 드리프트 감지 시스템을 구축하는 데 어떤 기술 스택이 필요한가요? A. 드리프트 감지 시스템 구축에는 데이터 파이프라인(Apache Kafka, AWS Kinesis 등), 데이터 저장소(데이터 레이크, 데이터 웨어하우스), 통계 분석 라이브러리(SciPy, NumPy), MLOps 플랫폼(MLflow, Kubeflow, Vertex AI, Sagemaker)이 필요합니다. 또한, 알림 시스템(Slack API, SMTP) 및 자동화된 재학습을 위한 CI/CD(Continuous Integration/Continuous Delivery) 도구(Jenkins, GitHub Actions)에 대한 이해도 중요합니다. 클라우드 기반의 관리형 MLOps 서비스들을 활용하면 초기 구축 비용과 시간을 크게 절감할 수 있습니다.
Q. 드리프트 감지 후 무조건 모델을 재학습해야 하나요? A. 꼭 그렇지는 않습니다. 드리프트의 종류와 심각성에 따라 대응 방식이 달라질 수 있습니다. 경미한 데이터 드리프트의 경우, 모델의 하이퍼파라미터를 조정하거나 데이터 전처리 방식을 개선하는 것으로 충분할 수도 있습니다. 하지만 모델 성능에 심각한 영향을 미치거나 개념 드리프트가 발생한 경우에는 새로운 데이터로 모델을 재학습시키는 것이 일반적입니다. 어떤 경우든, 재학습 전에 충분한 검증과 A/B 테스트를 거쳐야 합니다.
참고자료
- Gartner Predicts AI Risk Management Challenges in 2024 - Gartner (2024)
- The state of AI in 2024: Generative AI’s breakout year - McKinsey Global AI Survey (2024)
- The Forrester Wave™: AI/ML Platforms, Q3 2025 - Forrester (2025)
- Data Drift: A Practical Guide to Monitoring ML Models in Production - Evidently AI (2024)
- TensorFlow Extended (TFX) Data Validation Guide - TensorFlow (2025)
이 글이 도움이 되셨다면 공유해 주세요.


