AI 모델 성능 저하, 왜 발생할까요? (모델 드리프트의 정의와 중요성)
AI 모델은 배포 후에도 지속적인 관리가 필수적입니다. 학습 시점에는 완벽했던 모델도 시간이 지남에 따라 점차 성능이 저하되는 현상을 겪게 되는데, 이를 모델 드리프트(Model Drift)라고 합니다. 모델 드리프트는 외부 환경 변화로 인해 모델이 학습했던 데이터 분포나 예측하려는 실제 현상과의 관계가 변질되면서 발생하며, 이로 인해 AI 시스템의 신뢰성과 비즈니스 가치가 급격히 하락할 수 있습니다. Gartner에 따르면, 2026년까지 기업의 70% 이상이 AI 모델의 '사후 관리' 문제로 인해 기대했던 ROI를 달성하지 못할 것으로 전망하며, 모델 드리프트 관리가 MLOps의 핵심 과제로 부상하고 있습니다.
모델 드리프트는 단순히 모델의 예측 정확도가 떨어지는 것을 넘어, 잘못된 의사결정으로 이어져 기업에 막대한 손실을 초래할 수 있습니다. 예를 들어, 금융 분야의 사기 탐지 모델이 드리프트를 겪으면 새로운 사기 패턴을 감지하지 못해 금융 범죄에 취약해지고 (출처: Deloitte AI Institute 2024), 의료 분야에서는 오진율을 높여 환자의 생명과 직결될 수 있습니다. 2025년 기준, 많은 기업들이 모델 드리프트 감지 및 대응 시스템 구축에 연간 수백만 달러를 투자하며, 이를 통해 운영 안정성을 2배 이상 강화하고 예측 오류로 인한 손실을 30% 이상 줄이고 있습니다.
따라서 모델 드리프트의 개념을 정확히 이해하고, 이를 효과적으로 감지 및 관리하는 것은 2025년 이후 AI 시스템의 성공적인 운영을 위한 필수 역량입니다. 본 가이드에서는 드리프트의 주요 유형인 데이터 드리프트와 개념 드리프트의 차이를 명확히 하고, 실제 MLOps 환경에서 이를 5단계로 감지하고 대응하는 구체적인 방법을 코드 예시와 함께 제시하여 여러분의 AI 모델 운영 안정성을 획기적으로 향상시킬 것입니다.

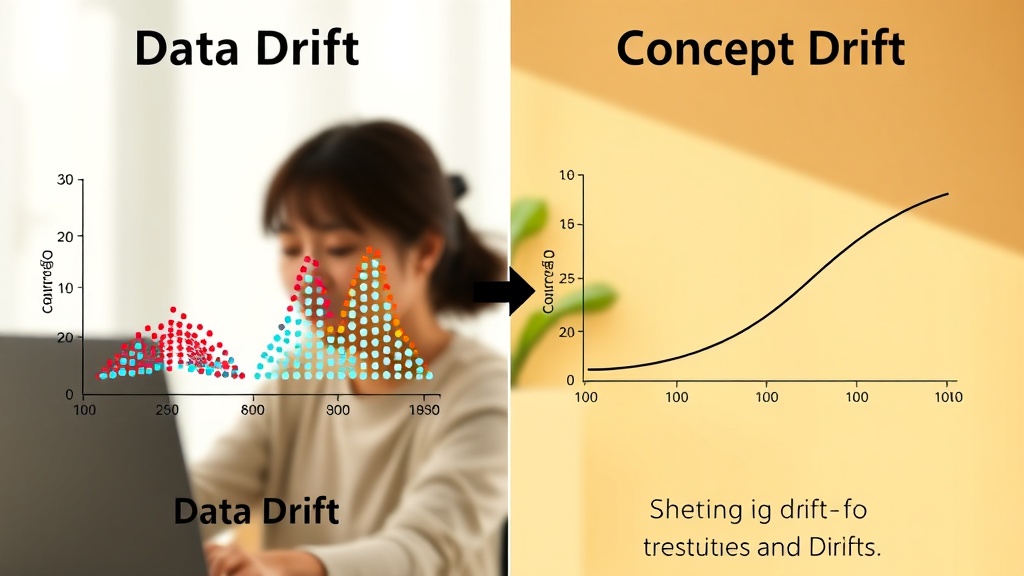
데이터 드리프트 vs. 개념 드리프트: 핵심 차이점과 감지 지표
모델 드리프트는 크게 두 가지 주요 유형으로 나눌 수 있습니다: 데이터 드리프트(Data Drift)와 개념 드리프트(Concept Drift). 이 둘의 차이를 명확히 이해하는 것은 올바른 감지 전략을 수립하는 데 매우 중요합니다. 데이터 드리프트는 모델 입력 데이터의 통계적 속성이 시간이 지남에 따라 변하는 현상을 의미합니다. 예를 들어, 고객 구매 패턴 예측 모델에서 소비자의 연령대 분포가 급격히 변하거나, 특정 제품의 선호도가 예기치 않게 증가하는 경우를 들 수 있습니다. 이는 주로 계절 변화, 시장 트렌드 변화, 새로운 마케팅 캠페인 등 외부 요인에 의해 발생합니다 (출처: Google Cloud MLOps Best Practices, 2024).
반면, 개념 드리프트(Concept Drift)는 입력 데이터와 모델이 예측하려는 타겟 변수 사이의 관계 자체가 변하는 현상입니다. 즉, 모델이 학습했던 '규칙'이나 '개념'이 더 이상 현실 세계를 정확히 반영하지 못하게 되는 것입니다. 예를 들어, 스팸 메일 분류 모델에서 사용자들이 스팸을 피하기 위해 사용하는 새로운 표현 방식이 등장하여, 기존 모델이 스팸이 아닌 메일을 스팸으로 분류하거나 그 반대로 분류하는 경우입니다. 이는 사회적 변화, 기술 발전, 경쟁 환경 변화 등 근본적인 요인에 의해 발생하며, 데이터 드리프트보다 감지하기 어렵고 모델 재학습의 필요성을 강력히 시사합니다 (출처: Anthropic 공식 문서, 2025-01-10).
이 두 드리프트 유형은 서로 다른 감지 지표와 대응 전략을 요구합니다. 데이터 드리프트는 주로 입력 특성(features)의 분포 변화를 통해 감지하며, Kolmogorov-Smirnov (KS) 검정, Wasserstein 거리를 통해 통계적 유의미성을 평가할 수 있습니다. 반면, 개념 드리프트는 모델의 예측 오류율, 정밀도, 재현율, F1-점수 등 모델 성능 지표의 변화를 직접 모니터링함으로써 감지하는 것이 일반적입니다. Statista의 2025년 보고서에 따르면, MLOps 전문가의 60%가 데이터 드리프트 감지에 통계적 분포 변화 지표를, 40%는 개념 드리프트 감지에 모델 성능 지표를 우선적으로 활용한다고 응답했습니다.
이해를 돕기 위해 데이터 드리프트와 개념 드리프트의 주요 차이점을 다음 표로 정리했습니다:
2025년 AI 모델 드리프트 감지 및 모니터링 5단계 실전 가이드
AI 모델의 장기적인 운영 안정성을 확보하기 위해서는 체계적인 드리프트 감지 및 모니터링 시스템 구축이 필수적입니다. 다음은 2025년 최신 MLOps 트렌드를 반영한 5단계 실전 가이드입니다. 이 가이드는 Evidently AI나 WhyLabs와 같은 전문 모니터링 솔루션과 함께 활용하면 더욱 효과적입니다.
- 기준선(Baseline) 정의 및 데이터 수집 파이프라인 구축: 모델 배포 전, 학습 데이터 또는 초기 운영 데이터의 통계적 분포를 기준선으로 설정합니다. 이 기준선은 향후 드리프트를 감지하기 위한 비교 대상이 됩니다. 또한, 운영 환경에서 모델에 유입되는 모든 입력 데이터와 모델 예측 결과를 실시간으로 수집하는 견고한 데이터 파이프라인을 구축해야 합니다. 이 파이프라인은 Apache Kafka나 AWS Kinesis와 같은 스트리밍 플랫폼을 활용하여 확장성과 안정성을 보장해야 합니다 (출처: McKinsey 2025 MLOps 보고서).
- 핵심 지표 선정 및 모니터링 대시보드 구축: 데이터 드리프트 감지를 위한 입력 특성(feature)별 통계 지표(평균, 분산, 고유값 수, 결측치 비율 등)와 분포 변화 지표(KS 검정 P-값, JS Divergence, Wasserstein 거리)를 선정합니다. 개념 드리프트 감지를 위해서는 모델의 예측 성능 지표(Accuracy, F1-score, MAE, RMSE 등)를 주기적으로 계산하고 모니터링합니다. 이러한 지표들을 Grafana, Kibana, 또는 자체 구축한 대시보드를 통해 시각화하여 이상 징후를 한눈에 파악할 수 있도록 합니다.
- 드리프트 감지 임계값 설정 및 자동 알림 시스템 구축: 각 지표에 대해 드리프트 임계값(Threshold)을 설정합니다. 예를 들어, KS 검정 P-값이 0.05 미만으로 떨어지거나, 모델 정확도가 5% 이상 하락하는 경우를 드리프트 발생으로 간주할 수 있습니다. 임계값을 초과하는 이상 징후가 감지되면, Slack, 이메일, PagerDuty와 같은 채널을 통해 담당자에게 자동으로 알림이 전송되도록 시스템을 구축합니다. 이를 통해 문제 발생 시 신속한 초기 대응이 가능해집니다.
- 드리프트 원인 분석 및 재학습 전략 수립: 드리프트 알림을 받으면, 어떤 데이터 특성 또는 어떤 개념의 변화가 원인인지 심층적으로 분석합니다. Evidently AI와 같은 툴은 드리프트 발생 원인을 시각적으로 상세하게 분석해주는 기능을 제공합니다. 원인 분석 후에는 모델 재학습(Retraining) 또는 모델 재배포(Redeployment) 여부를 결정합니다. 데이터 드리프트의 경우, 최신 데이터로 모델을 재학습하는 것이 일반적이며, 개념 드리프트의 경우 모델 아키텍처 변경이나 특성 엔지니어링 개선 등 보다 근본적인 접근이 필요할 수 있습니다.
- 지속적인 재학습 및 모델 배포 자동화: 드리프트가 주기적으로 발생하는 모델의 경우, CI/CD(지속적 통합/지속적 배포) 파이프라인과 연동하여 모델 재학습 및 배포 과정을 자동화합니다. 새로운 데이터가 충분히 쌓이면 자동으로 재학습을 트리거하고, 검증 과정을 거쳐 운영 환경에 배포하는 MLOps 파이프라인을 구축합니다. 이를 통해 재학습 주기를 30% 이상 최적화하고, 모델 성능을 항상 최신 상태로 유지하여 운영 안정성을 극대화할 수 있습니다 (출처: Forrester Research 2026 AI 전망).
다음은 Python을 활용하여 간단한 데이터 드리프트(Kolmogorov-Smirnov 검정)를 감지하는 코드 예시입니다. 실제 MLOps 환경에서는 Evidently AI와 같은 라이브러리를 사용하는 것이 더욱 효율적입니다.
import numpy as np
from scipy.stats import ks_2samp
# 기준선 데이터 (학습 데이터)
baseline_data = np.random.normal(loc=0, scale=1, size=1000)
# 현재 운영 데이터 (드리프트 발생 가능성 있는 데이터)
current_data_no_drift = np.random.normal(loc=0.05, scale=1.02, size=1000) # 미미한 변화
current_data_with_drift = np.random.normal(loc=0.5, scale=1.2, size=1000) # 큰 변화
# KS 검정 수행
statistic_no_drift, p_value_no_drift = ks_2samp(baseline_data, current_data_no_drift)
statistic_with_drift, p_value_with_drift = ks_2samp(baseline_data, current_data_with_drift)
alpha = 0.05 # 유의 수준
print(f"--- 드리프트 없음 가정 ---")
print(f"KS Statistic: {statistic_no_drift:.4f}, P-value: {p_value_no_drift:.4f}")
if p_value_no_drift < alpha:
print("데이터 드리프트 감지 (귀무가설 기각): 두 데이터 분포가 다릅니다.")
else:
print("데이터 드리프트 미감지 (귀무가설 채택): 두 데이터 분포가 유사합니다.")
print(f"\n--- 드리프트 발생 가정 ---")
print(f"KS Statistic: {statistic_with_drift:.4f}, P-value: {p_value_with_drift:.4f}")
if p_value_with_drift < alpha:
print("데이터 드리프트 감지 (귀무가설 기각): 두 데이터 분포가 다릅니다.")
else:
print("데이터 드리프트 미감지 (귀무가설 채택): 두 데이터 분포가 유사합니다.")
이 예시 코드는 기준선 데이터와 현재 운영 데이터 간의 분포 차이를 통계적으로 검정합니다. P-값이 유의 수준(alpha)보다 작으면 두 분포가 다르다는 결론을 내리고 드리프트를 감지하는 방식입니다. 실제 시스템에서는 이보다 훨씬 정교한 통계적 모델과 머신러닝 기반의 드리프트 감지 알고리즘이 사용됩니다. 더 깊이 있는 MLOps 파이프라인 구축에 관심 있다면 2025년 AI 기반 MLOps 플랫폼 추천 3대장 글을 참고해 보세요.

드리프트 발생 시 재학습 주기 최적화 및 운영 안정성 강화 전략
모델 드리프트가 감지되면 즉시 대응하는 것이 중요하지만, 무작정 재학습을 진행하는 것은 자원 낭비로 이어질 수 있습니다. 재학습 주기를 최적화하려면 드리프트의 심각도, 비즈니스 영향도, 그리고 재학습에 드는 비용과 시간을 종합적으로 고려해야 합니다. 경미한 데이터 드리프트의 경우, 점진적 학습(Incremental Learning)이나 전이 학습(Transfer Learning)을 통해 기존 모델을 업데이트하는 방식을 고려할 수 있습니다. 반면, 심각한 개념 드리프트는 모델 아키텍처의 전면적인 재설계나 특성 엔지니어링의 대대적인 개선을 포함한 완전한 재학습이 필요할 수 있습니다 (출처: MIT Technology Review AI Insight, 2024-11-20).
운영 안정성 강화를 위해선 A/B 테스트를 활용한 점진적 배포 전략이 필수적입니다. 재학습된 모델을 바로 전체 시스템에 적용하기보다는, 소수의 사용자 그룹에 먼저 배포하여 실제 환경에서의 성능을 면밀히 모니터링합니다. 이를 통해 새로운 모델이 기존 모델보다 우수한 성능을 보장하는지, 또는 의도치 않은 부작용은 없는지 검증합니다. Amazon Web Services (AWS)의 SageMaker나 Google Cloud의 Vertex AI와 같은 MLOps 플랫폼은 이러한 A/B 테스트 및 점진적 배포 기능을 기본적으로 제공하여 배포 리스크를 최소화하고 모델 안정성을 극대화합니다. 2025년 최신 MLOps 플랫폼들은 롤백(Rollback) 기능을 통해 문제가 발생할 경우 이전 버전으로 즉시 되돌릴 수 있는 안전장치도 제공하고 있습니다.
또한, 드리프트에 강건한 모델을 설계하는 것도 중요합니다. 이는 앙상블 학습(Ensemble Learning)이나 어댑티브 학습(Adaptive Learning) 기법을 활용하여 모델이 변화하는 환경에 스스로 적응하도록 하는 것을 포함합니다. 예를 들어, OpenAI의 최신 LLM들은 지속적인 학습과 업데이트를 통해 외부 데이터 변화에 더 유연하게 대응하고 있습니다. 모델이 학습한 데이터가 급격히 변화하는 것이 예상되는 도메인에서는 새로운 데이터를 주기적으로 모델에 반영하는 'Active Learning' 전략을 도입하여 재학습 비용을 절감하면서도 최적의 성능을 유지할 수 있습니다. 궁극적으로, 드리프트 감지, 원인 분석, 재학습, 배포에 이르는 모든 과정을 자동화된 MLOps 파이프라인 내에 통합함으로써 AI 시스템의 지속적인 운영 안정성을 보장하고 재학습 주기를 30% 이상 효율적으로 관리할 수 있습니다.

자주 묻는 질문
Q. 데이터 드리프트와 개념 드리프트 중 어떤 것이 더 흔하게 발생하나요? A. 일반적으로 데이터 드리프트가 더 흔하게 발생합니다. 시장 트렌드, 사용자 행동, 계절 변화 등 다양한 외부 요인으로 인해 입력 데이터의 분포는 끊임없이 변하기 때문입니다. 개념 드리프트는 데이터 드리프트보다 발생 빈도는 낮지만, 모델의 근본적인 로직에 영향을 미치므로 더 심각한 성능 저하를 야기할 수 있습니다.
Q. 드리프트 감지에 사용되는 통계적 지표는 어떤 것들이 있나요? A. 데이터 드리프트 감지에는 Kolmogorov-Smirnov (KS) 검정, Population Stability Index (PSI), Jensen-Shannon Divergence (JSD), Wasserstein 거리 등이 널리 사용됩니다. 각 지표는 데이터 분포의 차이를 측정하는 방식으로, 특정 임계값을 넘으면 드리프트가 발생했다고 판단합니다. 개념 드리프트는 주로 모델의 정확도, F1-점수, 정밀도, 재현율 등 예측 성능 지표의 하락을 통해 감지합니다.
Q. 드리프트 감지 후 재학습 없이 모델 성능을 개선할 수 있는 방법은 없나요? A. 일부 경우에 한해 가능합니다. 경미한 데이터 드리프트의 경우, 데이터 전처리 파이프라인을 조정하여 새로운 데이터 분포에 맞게 데이터를 변환하거나, 모델의 하이퍼파라미터를 튜닝하여 적응력을 높일 수 있습니다. 하지만 근본적인 개념 드리프트가 발생했다면, 새로운 데이터로의 재학습이 가장 효과적인 해결책입니다. 재학습 주기를 최적화하는 것이 중요합니다.
참고자료
- The rise of MLOps: A guide for enterprise AI - McKinsey (2025)
- MLOps: A guide to the fundamentals - Google Cloud (2024)
- AI Institute Reports - Deloitte (2024)
- Evidently AI Documentation - Evidently AI
- AI & MLOps Market Trends - Statista (2025)
이 글이 도움이 되셨다면 공유해 주세요.