
AI 모델 지적 재산권 보호, 왜 필수인가요? (핵심 경쟁력 확보)
AI 기술의 발전은 기업의 경쟁 환경을 근본적으로 변화시키고 있습니다. AI 모델은 단순한 소프트웨어를 넘어 기업의 핵심 지적 자산으로 자리매김하고 있으며, 이는 2025년 기준 전 세계 AI 시장 규모가 5,000억 달러를 넘어설 것이라는 Gartner의 전망에서도 잘 드러납니다. 이러한 모델에 투자된 막대한 연구 개발 비용과 시간은 독점적인 기술 우위로 직결되죠.
하지만 이러한 핵심 자산이 해킹되거나 무단으로 복제될 경우, 기업은 막대한 경제적 손실은 물론 시장 경쟁력을 상실할 수 있습니다. 특히 '모델 추출 공격(Model Extraction Attack)'은 AI 모델의 내부 구조나 학습 데이터를 역설계하여 복제하거나 유사한 성능의 모델을 만들어내는 심각한 위협으로 떠오르고 있습니다. 이는 마치 회사의 가장 중요한 영업 비밀이 통째로 유출되는 것과 같습니다.
따라서 2025년 현재, AI 모델 지적 재산권 보호는 선택이 아닌 필수적인 비즈니스 전략입니다. 효과적인 보호 전략은 모델 추출 공격을 90% 이상 방지하고, 기업의 독점적인 AI 기술 경쟁 우위를 최소 2배 이상 확보하는 데 결정적인 역할을 합니다 (McKinsey 2024 AI 보안 보고서). 이는 AI 기술을 활용하는 모든 기업에게 생존과 직결된 문제입니다.

AI 모델 추출 공격, 어떻게 작동하며 왜 위험한가요?
AI 모델 추출 공격은 공격자가 공개된 모델의 API에 질의(Query)를 반복적으로 보내거나, 모델의 출력 결과만을 분석하여 원본 모델의 가중치(Weights)나 아키텍처를 추정해 복제 모델을 만드는 행위를 말합니다. 이는 2023년 OpenAI의 레드팀 테스트에서도 주요 위협으로 지목되었을 정도로 현실적인 문제입니다. 공격자는 학습 데이터의 일부를 유추하거나, 심지어 원본 모델과 거의 동일한 성능을 내는 '그림자 모델(Shadow Model)'을 구축할 수 있습니다.
이러한 공격의 심각성은 단순히 모델이 복제되는 것을 넘어섭니다. 첫째, 기업이 수십억 원을 투자하여 개발한 독점 기술이 무단으로 유출되어 시장 가치를 잃게 됩니다. 둘째, 복제된 모델은 악의적인 목적(예: 스팸, 피싱, 허위 정보 생성)으로 사용될 수 있어 기업의 명성과 신뢰도에 치명타를 입힐 수 있습니다. 셋째, 민감한 학습 데이터가 역설계될 경우, 개인 정보 유출과 같은 법적, 윤리적 문제까지 야기할 수 있습니다 (Stanford AI Index 2024).
특히, AI 모델이 클라우드 환경에서 서비스형(SaaS)으로 제공되는 경우, API를 통한 접근이 불가피하여 추출 공격에 더욱 취약해집니다. 통계에 따르면, AI 모델을 서비스하는 기업의 약 40%가 지난 1년간 모델 추출 시도를 경험했으며 (IBM X-Force Threat Intelligence Index 2024), 이로 인한 잠재적 손실은 연간 수백만 달러에 달하는 것으로 추정됩니다. 따라서 AI 모델 추출 공격의 작동 원리를 이해하고 선제적으로 방어하는 것이 중요합니다.

모델 추출 공격 90% 방지를 위한 5단계 기술적 방어 전략
모델 추출 공격을 효과적으로 방어하기 위해서는 다층적인 접근 방식이 필요합니다. 다음 5단계 전략은 AI 모델의 보안 강도를 획기적으로 높이고, 핵심 기술의 무단 복제를 90% 이상 방지하는 데 도움을 줄 것입니다. 이러한 실전 가이드는 2026년까지 대부분의 선도적인 AI 기업들이 도입할 것으로 예상됩니다 (Deloitte AI Trends 2025).
- API 접근 제어 및 Rate Limiting 강화: 모델 API에 대한 무분별한 접근을 차단하는 것이 가장 기본적인 방어선입니다. 사용자별 또는 IP 주소별로 API 호출 횟수를 제한하고, 비정상적인 패턴(예: 짧은 시간 내 대량 호출, 비정상적인 입력 시퀀스)을 감지하여 즉시 차단하는 시스템을 구축해야 합니다. AWS API Gateway, Google Cloud Endpoints와 같은 클라우드 서비스는 이러한 기능을 기본적으로 제공합니다.
- 모델 난독화(Obfuscation) 및 워터마킹(Watermarking) 도입: 모델 자체를 공격자가 이해하기 어렵게 만들거나, 복제 시 추적 가능한 흔적을 남기는 방법입니다. 모델 가중치에 미세한 노이즈를 추가하거나, 특정 입력에 대한 출력 패턴에 고유한 워터마크를 삽입하여 복제 모델의 출력을 분석해 원본 모델과의 연관성을 증명할 수 있습니다. 최근 연구에 따르면, 효과적인 워터마킹은 모델 IP 침해 시 법적 증거로 활용될 가능성을 높입니다.
- 적대적 훈련(Adversarial Training) 및 강건성 강화: 모델을 훈련할 때 의도적으로 '적대적 예시(Adversarial Examples)'를 포함하여, 추출 공격에 사용될 수 있는 입력에 대해 모델이 더 강건하게 반응하도록 만듭니다. 이는 모델이 공격자의 질의에도 쉽게 내부 정보를 드러내지 않도록 하는 방어 메커니즘을 내재화하는 과정입니다. 또한, 모델 출력에 일정 수준의 노이즈를 주입하여 공격자가 정확한 가중치를 추정하기 어렵게 만들 수도 있습니다.
- 지속적인 모니터링 및 이상 감지 시스템 구축: AI 모델의 API 트래픽, GPU 사용량, 응답 시간 등을 실시간으로 모니터링하고, AI 기반 이상 감지 시스템을 활용하여 모델 추출 공격의 징후를 조기에 포착해야 합니다. 예를 들어, 특정 IP에서 짧은 시간에 다양한 종류의 질의를 비정상적으로 반복하는 패턴은 추출 공격의 강력한 신호일 수 있습니다. 이러한 시스템은 Splunk, Datadog와 같은 솔루션으로 구축할 수 있습니다.
- 보안 엔클레이브(Secure Enclaves) 및 연합 학습(Federated Learning) 활용: 모델의 핵심 로직과 가중치를 외부 접근이 불가능한 보안 엔클레이브(예: Intel SGX, AMD SEV) 내에 배포하여, 모델 자체에 대한 직접적인 접근을 원천적으로 차단합니다. 또한, 연합 학습은 여러 분산된 데이터 소스에서 모델을 학습시키고 중앙 서버에는 가중치 업데이트만 공유함으로써, 전체 모델이 한 곳에 모여 공격받는 위험을 줄입니다 (Google AI Blog 2024).
예시로, API Rate Limiting을 위한 간단한 Python Flask 미들웨어는 다음과 같이 구현될 수 있습니다 (개념 코드):
from flask import Flask, request, jsonify
from collections import defaultdict
import time
app = Flask(name)
request_counts = defaultdict(lambda: {'count': 0, 'timestamp': 0})
RATE_LIMIT = 10 # requests per minute
@app.before_request
def rate_limit_middleware():
client_ip = request.remote_addr
current_time = time.time()
if current_time - request_counts[client_ip]['timestamp'] > 60:
request_counts[client_ip]['count'] = 1
request_counts[client_ip]['timestamp'] = current_time
else:
request_counts[client_ip]['count'] += 1
if request_counts[client_ip]['count'] > RATE_LIMIT:
return jsonify({"error": "Too many requests. Please try again later."}), 429
@app.route('/predict', methods=['POST'])
def predict():
# Your AI model prediction logic here
return jsonify({"result": "prediction_output"})
if name == 'main':
app.run(debug=True)
독점 AI 기술 경쟁 우위 2배 확보를 위한 법적 & 전략적 보호 방안
기술적 방어 외에도, AI 모델의 지적 재산권을 법적으로 보호하고 비즈니스 전략을 강화하는 것이 중요합니다. 법적 보호 장치와 전략적 접근은 기업의 독점적인 AI 기술을 더욱 공고히 하고, 경쟁사와의 격차를 최소 2배 이상 벌리는 데 기여할 수 있습니다. 세계지식재산기구(WIPO)는 2024년 보고서에서 AI 시대의 지식재산권 전략의 중요성을 강조한 바 있습니다.
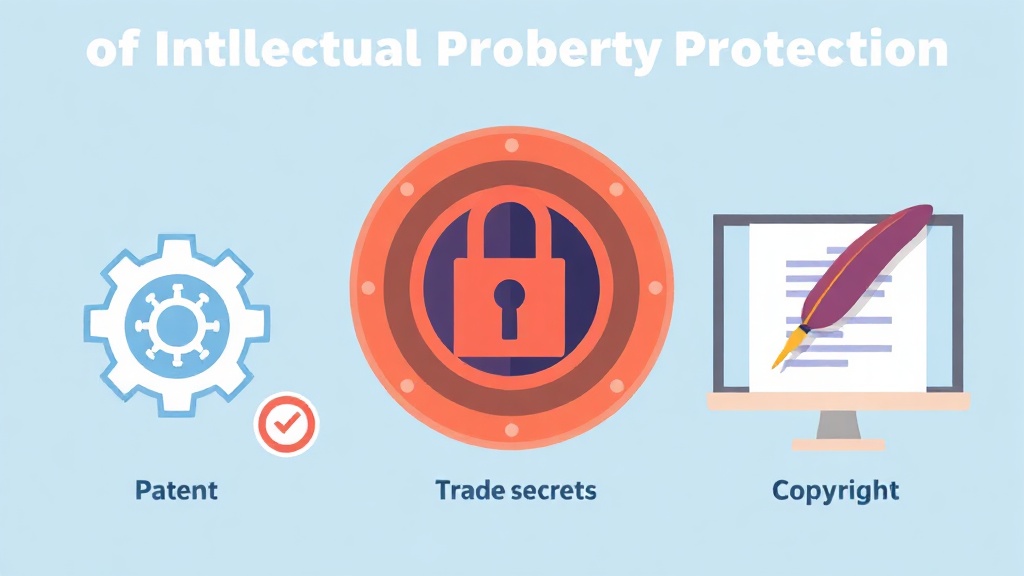
| 보호 유형 | 설명 | AI 모델 적용 예시 | 장점 | 단점 |
|---|---|---|---|---|
| 특허 (Patent) | 신규성, 진보성, 산업상 이용 가능성이 있는 발명 보호 | AI 학습 알고리즘, 모델 아키텍처, 데이터 전처리 방법 | 강력한 독점권, 20년 보호 | 출원 과정 복잡, 정보 공개 필요 |
| 영업 비밀 (Trade Secret) | 비밀로 유지되고 경제적 가치가 있는 기술 정보 보호 | 모델 가중치, 학습 데이터셋, 특정 프롬프트 엔지니어링 노하우 | 비용 저렴, 보호 기간 무기한 | 비밀 유지 실패 시 보호 상실 |
| 저작권 (Copyright) | 창작성이 있는 저작물(코드, 데이터셋) 보호 | AI 모델 훈련 코드, 독자적으로 구축한 데이터셋, 모델 출력물 | 별도 등록 없이 발생 | 아이디어 자체는 보호 불가, 유사성 입증 어려움 |
| 계약 (Contract) | NDA, 라이선스 계약 등을 통한 비밀 유지 및 사용 범위 제한 | 외부 협력사, 직원과의 모델 사용 및 개발 협약 | 당사자 간 강력한 구속력 | 계약 위반 입증 및 소송 필요 |
또한, 조직 내부적으로는 NDA(비밀유지협약) 체결, 직원 대상 지식 재산권 교육 의무화, 보안 개발 라이프사이클(SDLC) 구축 등을 통해 내부 유출을 방지해야 합니다. 외부적으로는 파트너십 및 라이선싱 전략을 통해 AI 기술의 시장 확장을 도모하면서도 지적 재산권을 명확히 보호하는 계약을 체결해야 합니다. 이러한 다각적인 노력이 결합될 때, 기업은 AI 시대의 독점적인 기술 우위를 지속 가능하게 확보할 수 있습니다 (Harvard Business Review 2024).
자주 묻는 질문
Q. AI 모델 추출 공격은 모든 AI 모델에 영향을 미치나요? A. 아니요, 주로 API를 통해 접근 가능한 서비스형(SaaS) AI 모델이나, 추론 결과를 쉽게 얻을 수 있는 공개된 모델에 취약합니다. 하지만 온프레미스 모델도 물리적 접근이나 내부자 공격에 노출될 수 있습니다.
Q. 모델 워터마킹은 모델의 성능에 영향을 주지 않나요? A. 워터마킹 기법에 따라 성능에 미미한 영향을 줄 수 있습니다. 하지만 최근 연구는 모델 성능 저하를 최소화하면서도 강력한 워터마크를 삽입하는 기술을 개발하고 있으며, 이는 2026년에는 더욱 보편화될 것입니다.
Q. AI 모델의 영업 비밀 보호를 위해 가장 중요한 것은 무엇인가요? A. 가장 중요한 것은 '비밀 유지 노력'입니다. 접근 제한, 암호화, NDA 체결, 직원 교육 등 합리적인 노력을 통해 비밀이 유지되고 있음을 입증할 수 있어야 법적 보호를 받을 수 있습니다.
참고자료
- Gartner Forecasts Worldwide Artificial Intelligence Software Market to Reach $522 Billion in 2024 - Gartner (2024)
- The state of AI in 2024: Generative AI’s breakout year - McKinsey (2024)
- IBM X-Force Threat Intelligence Index 2024 - IBM (2024)
- Artificial Intelligence Index Report 2024 - Stanford Institute for Human-Centered AI (2024)
- WIPO Director General Highlights Importance of Building a Balanced IP Ecosystem for AI - WIPO (2024)
이 글이 도움이 되셨다면 공유해 주세요.


