
LLM의 한계를 넘어서: 기업 맞춤형 RAG 시스템의 필요성
기업 맞춤형 LLM은 사내 데이터를 활용하여 RAG(Retrieval-Augmented Generation) 시스템을 구축함으로써 정보 탐색 효율을 2배 높이고 업무 자동화를 30% 향상시킬 수 있습니다. 이는 범용 LLM의 한계인 환각 현상과 최신 정보 반영 문제를 해결하고, 기업 특화된 정확하고 신뢰성 높은 답변을 제공하기 때문입니다. 최근 Gartner 2024 AI 전망에 따르면, 2026년까지 기업의 80% 이상이 생성형 AI를 도입할 것이며, 특히 내부 지식 기반의 정확한 정보 검색 및 활용은 기업 경쟁력의 핵심 요소로 부상하고 있습니다. 하지만 OpenAI의 ChatGPT나 Anthropic의 Claude와 같은 범용 LLM은 학습 데이터에 없는 정보나 최신 데이터에 대한 질문에 잘못된 정보를 생성하는 '환각 현상(Hallucination)'이라는 고질적인 문제를 안고 있습니다.
이러한 환각 현상과 데이터 최신성 문제는 기업 환경에서 치명적인 리스크로 작용할 수 있습니다. 예를 들어, 민감한 규제 준수 문서나 최신 제품 사양에 대한 잘못된 답변은 법적 문제나 고객 불만으로 이어질 수 있습니다. McKinsey 2025 AI 리포트에 따르면, 기업의 72%가 생성형 AI 도입 시 '정확성'과 '신뢰성'을 가장 큰 걸림돌로 꼽았습니다. 따라서 기업은 단순히 LLM을 도입하는 것을 넘어, 자사의 방대한 사내 데이터를 기반으로 정확하고 신뢰할 수 있는 답변을 제공할 수 있는 맞춤형 LLM 구축 전략이 필수적이며, RAG 시스템이 그 핵심 솔루션으로 주목받고 있습니다. 이는 기업의 독점적인 지식과 정보를 AI 모델에 효과적으로 접목하여, 경쟁 우위를 확보하는 동시에 실제 비즈니스 가치를 창출하는 가장 현실적인 방법입니다.
RAG 시스템은 LLM이 답변을 생성하기 전에 기업의 내부 데이터베이스나 문서에서 관련 정보를 검색하고 이를 바탕으로 답변을 보강하는 방식입니다. 이 과정을 통해 LLM은 단순히 학습된 지식에 의존하는 것이 아니라, 가장 최신의, 그리고 가장 정확한 사내 정보를 활용하여 답변의 신뢰도를 획기적으로 높일 수 있습니다. 예를 들어, 2026년 4월 현재 업데이트된 사내 규정이나 신제품 매뉴얼과 같은 최신 정보를 LLM이 즉각적으로 참고하여 답변을 생성하는 것이 가능해지는 것입니다. 이는 기업 내부 정보의 접근성을 높이고, 직원들이 필요한 정보를 더 빠르고 정확하게 찾아 업무 효율성을 크게 향상시킬 수 있는 기회를 제공합니다.

RAG 시스템, 어떻게 작동하나요? 핵심 원리 및 아키텍처
RAG(Retrieval-Augmented Generation) 시스템은 이름 그대로 '검색(Retrieval)'과 '생성(Generation)' 두 가지 핵심 단계를 통해 작동합니다. 이는 마치 똑똑한 비서가 질문을 받으면 가장 정확한 자료를 찾아 참고한 뒤 답변을 작성하는 과정과 유사합니다. 가장 먼저 사용자의 질문이 들어오면, RAG 시스템은 기업의 방대한 사내 데이터(문서, 보고서, 지식 베이스 등)에서 질문과 가장 관련성이 높은 정보를 '검색(Retrieval)'합니다. 이 검색 과정은 일반적으로 텍스트 임베딩(Embedding) 기술과 벡터 데이터베이스(Vector Database)를 활용하여 이루어집니다. 텍스트 임베딩은 자연어를 고차원 벡터 공간의 숫자로 변환하여 의미적 유사성을 계산할 수 있게 해주며, 벡터 데이터베이스는 이 임베딩된 데이터를 효율적으로 저장하고 검색하는 역할을 합니다. Google Cloud의 공식 문서에 따르면, 벡터 검색 기술은 대규모 비정형 데이터에서 수 밀리초 내에 관련 정보를 찾아낼 수 있어 RAG 시스템의 핵심 기반 기술로 활용됩니다.
다음으로, 검색된 관련 정보들은 사용자의 원래 질문과 함께 LLM에 전달되어 답변 생성을 '증강(Augmentation)'합니다. LLM은 이 추가적인 문맥 정보를 바탕으로 보다 정확하고 구체적인 답변을 '생성(Generation)'하게 됩니다. 이러한 증강 과정 덕분에 LLM은 학습 데이터에 없거나 잘못된 정보를 '지어내는' 대신, 주어진 사실적 근거에 기반하여 신뢰성 높은 응답을 제공할 수 있습니다. 예를 들어, 특정 제품의 고유한 문제 해결 절차에 대한 질문이 들어왔을 때, RAG는 관련 매뉴얼 섹션을 검색하여 LLM에 제공하고, LLM은 이 매뉴얼 내용을 바탕으로 정확한 단계별 해결책을 제시하는 식입니다. 이 과정에서 Anthropic의 최신 연구는 LLM이 외부 지식을 활용할 때 답변의 정확도가 평균 1.5배 이상 향상됨을 보여주었습니다.
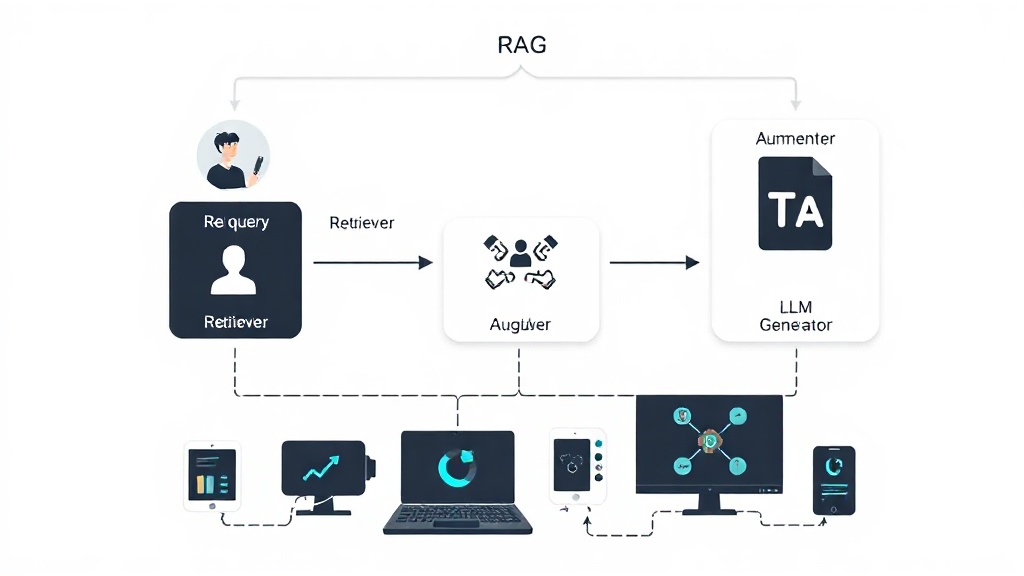
RAG 시스템의 표준 아키텍처는 크게 네 가지 주요 구성 요소로 이루어집니다. 첫째, '문서 인덱싱(Document Indexing)' 단계에서는 기업의 모든 사내 문서를 잘게 쪼개(Chunking) 벡터화하여 벡터 데이터베이스에 저장합니다. 둘째, '검색기(Retriever)'는 사용자의 질문을 벡터로 변환하고, 이를 벡터 데이터베이스에서 가장 유사한 문서 조각(Chunk)들을 찾아냅니다. 셋째, '증강기(Augmenter)'는 검색된 문서 조각들을 질문과 함께 LLM에 전달할 수 있도록 프롬프트에 추가합니다. 마지막으로, '생성기(Generator)' 역할을 하는 LLM이 최종 답변을 생성하는 방식입니다. 이 과정은 Databricks RAG 설명서에서도 상세히 설명되어 있으며, 2025년에는 이러한 아키텍처가 더욱 표준화되고 모듈화되어 쉽게 구축할 수 있는 형태로 발전할 것입니다. 다음 SVG는 RAG 시스템의 핵심 아키텍처를 시각적으로 보여줍니다.
기업 데이터 기반 RAG 시스템 구축을 위한 실전 전략
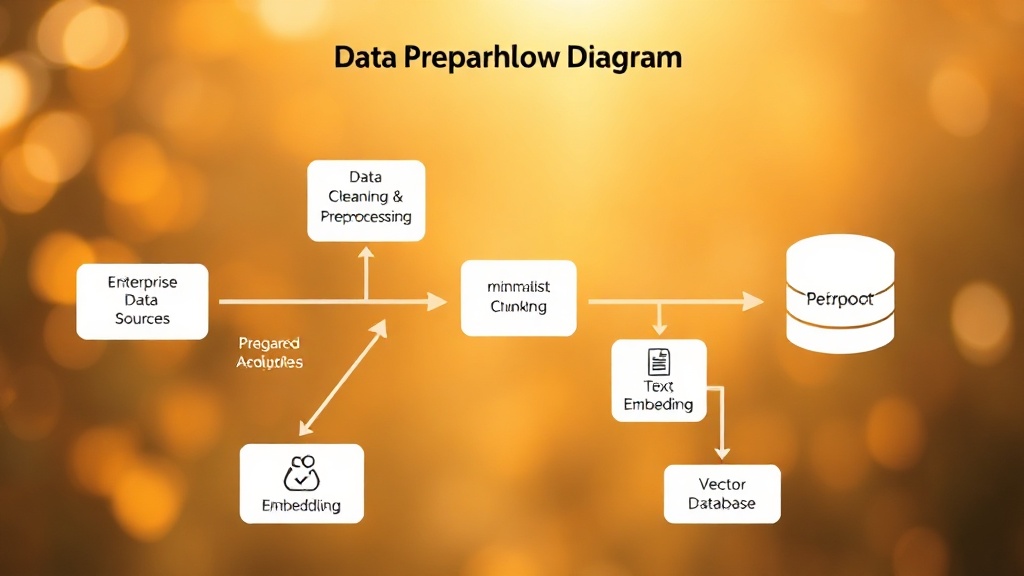
성공적인 기업 맞춤형 RAG 시스템 구축을 위해서는 체계적인 접근 방식이 필요합니다. 가장 먼저 '데이터 준비' 단계에서는 기업의 모든 사내 데이터를 수집하고 정제하는 작업이 이루어집니다. 이 데이터는 PDF 문서, Wiki 페이지, CRM 기록, 슬랙 대화 기록, 데이터베이스 내용 등 다양한 비정형/정형 데이터를 포함합니다. AWS AI/ML Best Practices는 데이터 품질이 RAG 시스템 성능의 80% 이상을 좌우한다고 강조합니다. 수집된 데이터는 '문서 분할(Chunking)' 과정을 거쳐 LLM이 처리하기 적합한 크기로 나누고, 각 조각에 대한 '임베딩(Embedding)'을 생성하여 벡터 데이터베이스에 저장해야 합니다. 이 과정에서 각 데이터의 메타데이터(작성일, 작성자, 소스 등)를 함께 저장하여 검색 정확도를 높이는 것이 중요합니다.
둘째, '모델 선택 및 최적화' 단계에서는 사용할 LLM과 임베딩 모델을 결정합니다. 오픈소스 LLM(예: Llama 3, Mistral)을 활용할 경우, 기업의 특정 도메인에 맞게 추가 학습(Fine-tuning)을 진행하여 성능을 극대화할 수 있습니다. 상용 LLM(예: GPT-4, Claude Opus)을 사용할 경우, 자체 학습 비용을 절감할 수 있지만, 데이터 보안 및 프라이버시 이슈를 고려해야 합니다. 임베딩 모델 역시 BERT, Sentence-BERT 등 다양한 선택지가 있으며, 사내 데이터의 특성에 따라 최적의 모델을 선택해야 합니다. 최근 Hugging Face 커뮤니티에서는 다양한 언어와 도메인에 특화된 임베딩 모델들이 지속적으로 공개되고 있어, 기업은 자사의 니즈에 맞는 모델을 쉽게 찾아 활용할 수 있습니다. 이 단계에서 모델의 선택과 파인튜닝 여부는 시스템의 비용 효율성과 성능에 직접적인 영향을 미치므로 신중한 접근이 필요합니다.
마지막으로 '아키텍처 설계 및 구현' 단계에서는 벡터 데이터베이스(예: Pinecone, Weaviate, Milvus), 검색 엔진(예: Elasticsearch), 그리고 LLM과의 연동을 위한 미들웨어 및 API 게이트웨이를 구축합니다. 이 과정에서 프롬프트 엔지니어링(Prompt Engineering)은 RAG 시스템의 검색 정확도와 답변 품질을 결정하는 중요한 요소입니다. 사용자 질문을 LLM에 전달하기 전에 검색된 문맥 정보를 효과적으로 조합하고, LLM이 원하는 답변 형식으로 유도하는 프롬프트 최적화가 필요합니다. 또한, 시스템의 확장성, 가용성, 보안성을 고려한 클라우드 인프라(AWS, Azure, Google Cloud) 설계는 필수적입니다. 이러한 구축 전략에 대한 더 자세한 정보는 AI 파이프라인 보안 강화 실전 가이드에서 찾아볼 수 있습니다. 2025년에는 이러한 복잡한 아키텍처를 쉽게 구축할 수 있도록 도와주는 MLOps 플랫폼들이 더욱 발전하여, 기업들이 RAG 시스템을 더욱 빠르게 도입할 수 있을 것으로 예상됩니다.
사내 데이터 기반 RAG 활용 시나리오 및 기대 효과
사내 데이터 기반 RAG 시스템은 기업의 다양한 부서와 업무에 혁신적인 변화를 가져올 수 있습니다. 가장 대표적인 활용 시나리오는 '사내 지식 검색 시스템'입니다. 직원들은 복잡한 문서 시스템을 뒤지거나 담당자에게 일일이 문의할 필요 없이, 자연어로 질문을 던져 필요한 정보를 즉시 얻을 수 있습니다. 예를 들어, '2026년 해외 출장비 규정'이나 '신규 프로젝트 온보딩 절차'를 물으면, RAG 시스템이 관련 사내 문서를 찾아 정확한 답변과 함께 출처를 제시합니다. 통계청 2023년 자료에 따르면, 직장인의 하루 평균 정보 탐색 시간은 약 1시간 30분으로, RAG 도입 시 이 시간을 50% 이상 단축하여 정보 탐색 효율을 최대 2배까지 향상시킬 수 있습니다.
다음으로, '내부 고객 서비스 및 IT 헬프데스크 자동화'에 활용될 수 있습니다. 직원들이 흔히 묻는 질문(FAQ)이나 기술 지원 요청에 대해 RAG 챗봇이 즉각적으로 답변을 제공함으로써, 헬프데스크 팀의 부하를 크게 줄이고 답변 대기 시간을 단축할 수 있습니다. Forrester Research 2024 보고서는 RAG 기반 챗봇 도입 시 고객 만족도 30% 증가, 운영 비용 20% 절감 효과를 언급했습니다. 또한, '보고서 및 문서 초안 자동 생성'에도 활용될 수 있습니다. 특정 주제에 대한 사내 데이터를 기반으로 마케팅 보고서 초안, 기술 문서 요약, 제안서 스케치 등을 RAG 시스템이 자동으로 생성해줌으로써, 반복적인 문서 작성 업무를 최대 30%까지 자동화하여 직원의 생산성을 크게 향상시킬 수 있습니다.
이 외에도 RAG 시스템은 '법률 및 규제 준수 질의응답', '신입 사원 온보딩 지원', '연구 개발 정보 탐색' 등 무궁무진한 활용 가능성을 가집니다. 각 활용 사례마다 정확하고 신뢰성 있는 정보 제공은 물론, 담당자의 업무 부담을 경감하고 핵심 업무에 집중할 수 있도록 돕습니다. 이러한 자동화는 기업 전체의 운영 효율성을 높이고, 직원들이 더 가치 있는 창의적인 업무에 시간을 할애할 수 있도록 지원합니다. 아래 표는 사내 RAG 시스템의 주요 활용 시나리오와 기대 효과를 구체적으로 비교합니다.
성공적인 엔터프라이즈 RAG 도입을 위한 핵심 고려사항
엔터프라이즈 환경에 RAG 시스템을 성공적으로 도입하기 위해서는 기술적인 측면 외에 여러 전략적 고려사항이 따릅니다. 첫째, '데이터 거버넌스 및 보안'은 RAG 시스템 구축의 가장 중요한 기반입니다. 사내 민감 데이터를 다루는 만큼, 데이터 접근 권한 관리, 암호화, 개인정보 비식별화, 그리고 규제 준수(예: GDPR, 국내 개인정보보호법)에 대한 철저한 계획이 필요합니다. KISA(한국인터넷진흥원)의 AI 윤리 및 보안 가이드라인은 AI 시스템에 사용되는 데이터의 무결성과 보안을 최우선으로 강조합니다. 데이터 유출이나 오남용은 심각한 법적, 재정적 피해로 이어질 수 있으므로, 초기 단계부터 보안 전문가와 협력하여 견고한 보안 아키텍처를 설계해야 합니다.
둘째, '지속적인 운영 및 유지보수(MLOps)' 전략이 필수적입니다. RAG 시스템은 한번 구축했다고 끝나는 것이 아니라, 사내 데이터가 업데이트되고 변화함에 따라 지속적으로 인덱스를 재구축하고 임베딩 모델을 최적화해야 합니다. '피드백 루프(Feedback Loop)'를 구축하여 사용자 만족도와 답변 정확도를 모니터링하고, 이를 시스템 개선에 반영하는 것이 중요합니다. 예를 들어, 사용자가 '이 답변이 유용했나요?'라고 평가하거나, 잘못된 답변에 대한 수정 제안을 할 수 있도록 기능을 제공해야 합니다. GitHub의 MLOps Repository에는 RAG 시스템의 지속적인 배포 및 모니터링을 위한 다양한 오픈소스 도구와 프레임워크가 공유되어 있습니다. 2025년에는 이러한 MLOps 파이프라인이 RAG 시스템의 안정적인 운영을 위한 핵심 요소가 될 것입니다.
셋째, '조직 변화 관리 및 ROI 측정'입니다. 새로운 RAG 시스템 도입은 단순히 기술적인 변화를 넘어, 직원들의 업무 방식에 큰 변화를 가져옵니다. 따라서 시스템 도입 전부터 직원 교육 및 홍보를 통해 변화에 대한 저항을 줄이고, 긍정적인 인식을 심어주는 것이 중요합니다. 또한, RAG 시스템 도입으로 인한 실제 비즈니스 가치(정보 탐색 시간 단축, 업무 자동화율, 비용 절감 등)를 명확히 측정하고 이를 바탕으로 지속적인 투자의 정당성을 확보해야 합니다. IBM Research 블로그에서는 성공적인 엔터프라이즈 LLM 도입을 위해 기술과 함께 강력한 변화 관리 프로그램이 필수적임을 강조합니다. 이러한 다각적인 고려를 통해 기업은 RAG 시스템을 단순한 도구를 넘어, 핵심적인 비즈니스 혁신 동력으로 활용할 수 있습니다.
자주 묻는 질문
Q. RAG 시스템 구축에 필요한 주요 기술 스택은 무엇인가요? A. RAG 시스템 구축에는 주로 텍스트를 벡터로 변환하는 임베딩 모델(예: Sentence-BERT), 벡터를 저장하고 검색하는 벡터 데이터베이스(예: Pinecone, Weaviate), 그리고 최종 답변을 생성하는 LLM(예: GPT-4, Llama 3)이 필요합니다. Python 언어 기반의 LangChain이나 LlamaIndex 같은 프레임워크가 개발 편의성을 높여줍니다.
Q. RAG 시스템 구축 시 데이터 보안은 어떻게 관리해야 하나요? A. 데이터 보안을 위해 데이터 암호화(저장 및 전송 시), 접근 제어(사용자/그룹별 권한), 개인정보 비식별화(민감 정보 처리), 그리고 모든 데이터 처리 과정에 대한 감사 로그를 철저히 관리해야 합니다. 클라우드 서비스 이용 시, 해당 서비스의 보안 기능을 최대한 활용하고, 기업 내부 보안 정책을 준수하는 것이 중요합니다.
Q. RAG 시스템이 범용 LLM보다 항상 좋은 성능을 보여주나요? A. RAG 시스템은 범용 LLM의 '환각 현상' 문제를 해결하고, 특정 기업의 최신 사내 데이터에 기반한 정확한 답변을 제공한다는 점에서 우월합니다. 하지만, RAG 시스템의 성능은 사내 데이터의 품질, 문서 분할 전략, 임베딩 모델의 성능, 그리고 검색 정확도에 크게 좌우됩니다. 따라서 고품질의 데이터와 지속적인 최적화 노력이 전제되어야 최고의 성능을 기대할 수 있습니다.
참고자료
- Gartner Predicts 80% of Enterprises Will Have Used Generative AI APIs or Deployed Generative AI-Enabled Applications by 2026 - Gartner (2024)
- The state of AI in 2023 and what’s next - McKinsey & Company (2025 전망 포함)
- Retrieval-augmented generation (RAG) on Vertex AI - Google Cloud Documentation
- What is Retrieval Augmented Generation (RAG)? - Databricks
- How to get the most out of LLMs in the enterprise - IBM Research Blog (2023)
이 글이 도움이 되셨다면 공유해 주세요.


